Pinecone integration
Pinecone is a managed vector database that allows users to store and query dense vectors for AI applications such as recommendation systems, semantic search, and retrieval augmented generation (RAG).
The Apify integration for Pinecone enables you to export results from Apify Actors and Dataset items into a specific Pinecone vector index.
This integration uses a third-party service. If you find outdated content, please submit an issue on GitHub.
Prerequisites
Before you begin, ensure that you have the following:
- A Pinecone database and index set up.
- A Pinecone index created & Pinecone API token obtained.
- An OpenAI API key to compute text embeddings.
- An Apify API token to access Apify Actors.
How to setup Pinecone database and create an index
-
Sign up or log in to your Pinecone account and click on Create Index.
-
Specify the following details: index name, vector dimension, vector distance metric, deployment type (serverless or pod), and cloud provider.
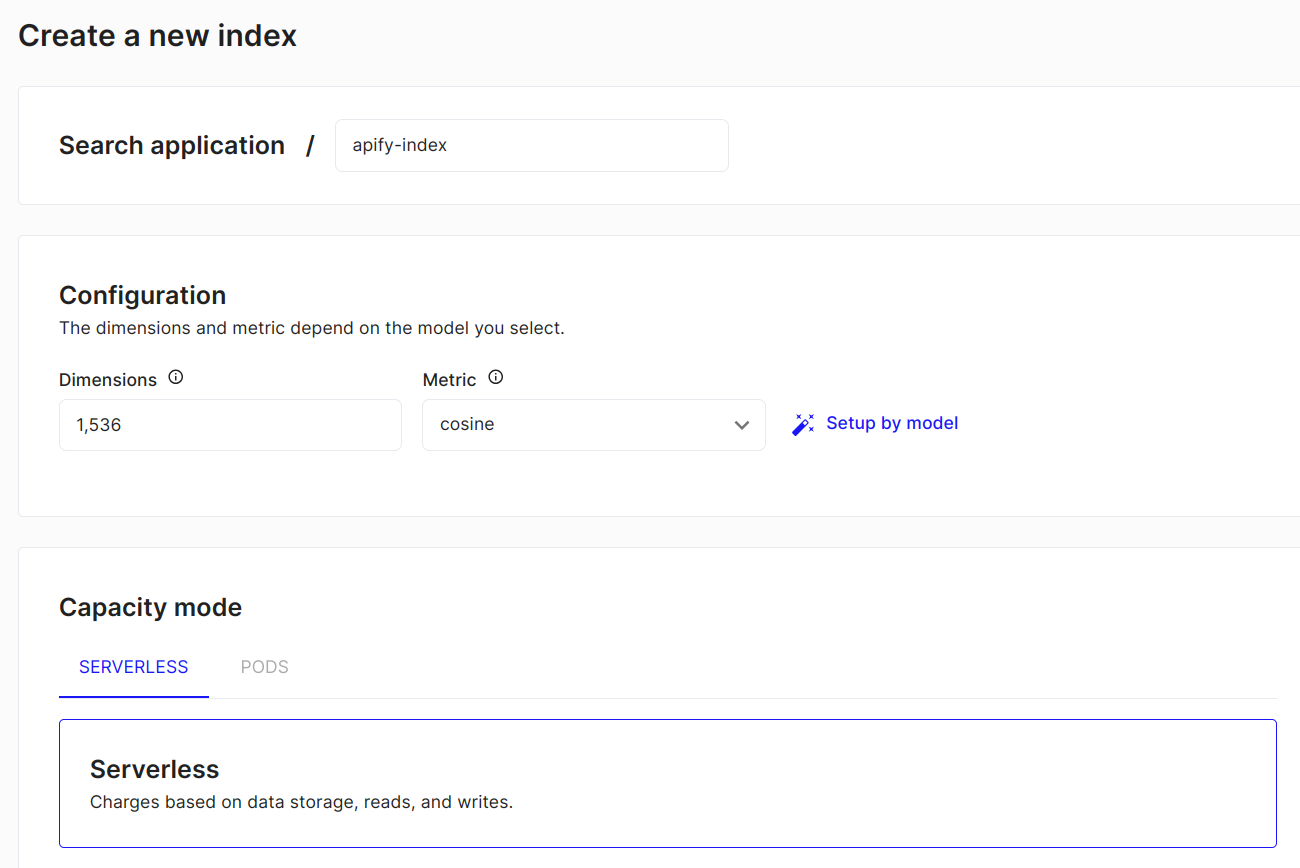
Once the index is created and ready, you can proceed with integrating Apify.
Integration Methods
You can integrate Apify with Pinecone using either Apify Console or the Apify Python SDK.
The examples utilize the Website Content Crawler Actor, which deeply crawls websites, cleans HTML by removing modals and navigation elements, and converts HTML to Markdown for training AI models or providing web content to LLMs and generative AI applications.
Apify Console
-
Set up the Website Content Crawler Actor in the Apify Console. Refer to this guide on how to set up website content crawl for your project.
-
Once you have the crawler ready, navigate to the integration section and add Apify’s Pinecone integration.
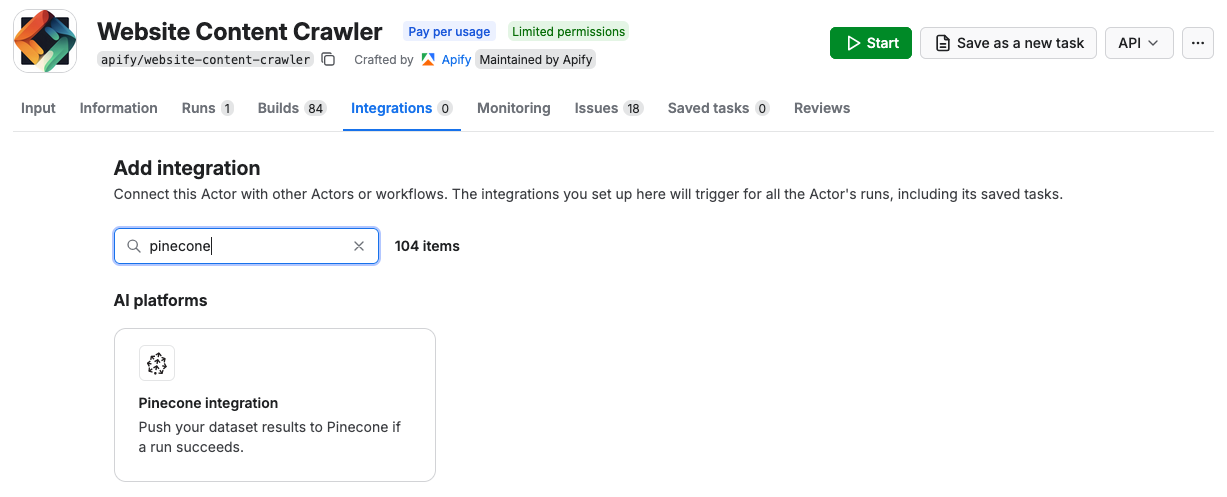
-
Select when to trigger this integration (typically when a run succeeds) and fill in all the required fields for the Pinecone integration. You can learn more about the input parameters at the Pinecone integration input schema.
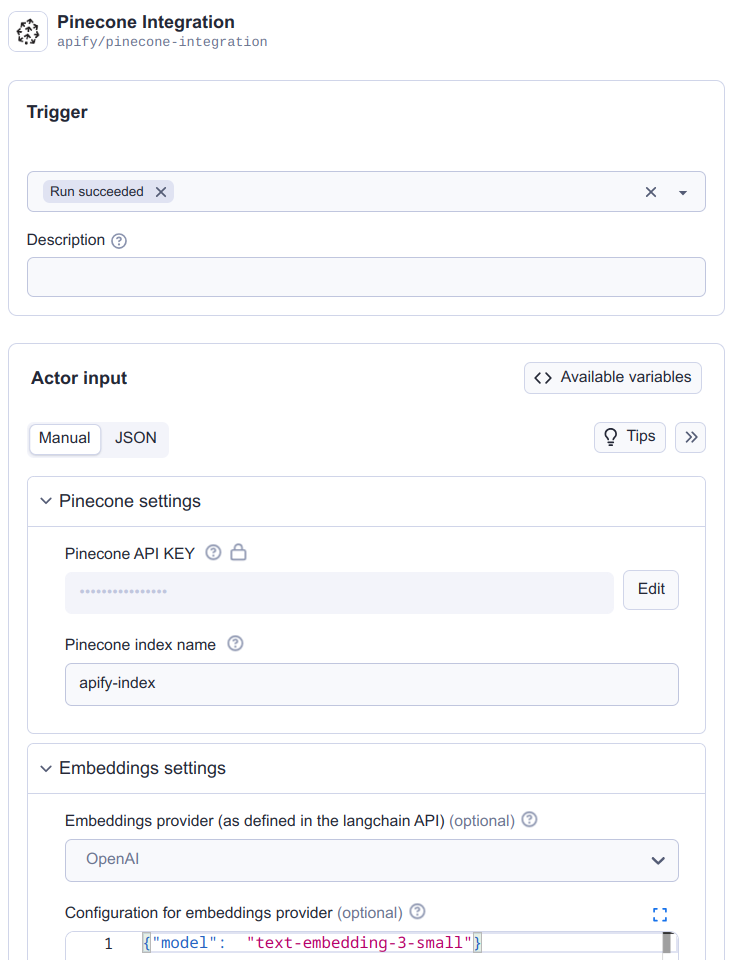
You need to ensure that your embedding model in the Pinecone index configuration matches the Actor settings.
For example, the text-embedding-3-small model from OpenAI generates vectors of size 1536, so your Pinecone index should be configured for vectors of the same size.
-
For a detailed explanation of the input parameters, including dataset settings, incremental updates, and examples, see the Pinecone integration description.
-
For an explanation on how to combine Actors to accomplish more complex tasks, refer to the guide on Actor-to-Actor integrations.
Python
Another way to interact with Pinecone is through the Apify Python SDK.
-
Install the Apify Python SDK by running the following command:
pip install apify-client -
Create a Python script and import all the necessary modules:
from apify_client import ApifyClient
APIFY_API_TOKEN = "YOUR-APIFY-TOKEN"
OPENAI_API_KEY = "YOUR-OPENAI-API-KEY"
PINECONE_API_KEY = "YOUR-PINECONE-API-KEY"
PINECONE_INDEX_NAME = "YOUR-PINECONE-INDEX-NAME"
client = ApifyClient(APIFY_API_TOKEN) -
Call the Website Content Crawler Actor to crawl the Pinecone documentation and extract text content from the web pages:
actor_call = client.actor("apify/website-content-crawler").call(
run_input={"startUrls": [{"url": "https://docs.pinecone.io/home"}]}
)
print("Website Content Crawler Actor has finished")
print(actor_call) -
Use Apify's Pinecone integration to store all the selected data from the dataset (provided by
datasetIdfrom the Actor call) into the Pinecone vector database.pinecone_integration_inputs = {
"pineconeApiKey": PINECONE_API_KEY,
"pineconeIndexName": PINECONE_INDEX_NAME,
"datasetFields": ["text"],
"datasetId": actor_call["defaultDatasetId"],
"enableDeltaUpdates": True,
"deltaUpdatesPrimaryDatasetFields": ["url"],
"deleteExpiredObjects": True,
"expiredObjectDeletionPeriodDays": 30,
"embeddingsApiKey": OPENAI_API_KEY,
"embeddingsProvider": "OpenAI",
"performChunking": True,
"chunkSize": 1000,
"chunkOverlap": 0,
}
actor_call = client.actor("apify/pinecone-integration").call(run_input=pinecone_integration_inputs)
print("Apify's Pinecone Integration has finished")
print(actor_call)
You have successfully integrated Apify with Pinecone and the data is now stored in the Pinecone vector database.