OpenAI Assistants integration
OpenAI Assistants API allows you to build your own AI applications such as chatbots, virtual assistants, and more. The OpenAI Assistants can access OpenAI knowledge base (vector store) via file search and use function calling for dynamic interaction and data retrieval.
Unlike Custom GPT, OpenAI Assistants are available via API, enabling integration with Apify to automatically update assistant data and deliver real-time information, improving the quality of answers.
In this tutorial, we’ll start by demonstrating how to create an assistant and integrate real-time data using function calling with the RAG Web Browser. Next, we’ll show how to save data from Apify Actors into the OpenAI Vector Store for easy retrieval through file-search.
This integration uses a third-party service. If you find outdated content, please submit an issue on GitHub.
Real-time search data for OpenAI Assistant
We'll use the RAG Web Browser Actor to fetch the latest information from the web and provide it to the OpenAI Assistant through function calling. To begin, we need to create an OpenAI Assistant with the appropriate instructions. After that, we can initiate a conversation with the assistant by creating a thread, adding messages, and running the assistant to receive responses. The image below provides an overview of the entire process:

Before we start creating the assistant, we need to install all dependencies:
pip install apify-client openai
Import all required packages:
import json
import time
from apify_client import ApifyClient
from openai import OpenAI, Stream
from openai.types.beta.threads.run_submit_tool_outputs_params import ToolOutput
Find your Apify API token and OpenAI API key and initialize OpenAI and Apify clients:
client = OpenAI(api_key="YOUR OPENAI API KEY")
apify_client = ApifyClient("YOUR APIFY API TOKEN")
First, let us specify assistant's instructions. Here, we ask the assistant to always provide answers based on the latest information from the internet and include relevant sources whenever possible. In a real-world scenario, you can customize the instructions based on your requirements.
INSTRUCTIONS = """ You are a smart and helpful assistant. Maintain an expert, friendly, and informative tone in your responses.
Your task is to answer questions based on information from the internet.
Always call call_rag_web_browser function to retrieve the latest and most relevant online results.
Never provide answers based solely on your own knowledge.
For each answer, always include relevant sources whenever possible.
"""
Next, we define a function description with two parameters, search query (query) and number of results we need to retrieve (maxResults).
RAG Web Browser can be called with more parameters, check the Actor input schema for details.
rag_web_browser_function = {
"type": "function",
"function": {
"name": "call_rag_web_browser",
"description": "Query Google search, scrape the top N pages from the results, and returns their cleaned content as markdown",
"parameters": {
"type": "object",
"properties": {
"query": { "type": "string", "description": "Use regular search words or enter Google Search URLs. "},
"maxResults": {"type": "integer", "description": "The number of top organic search results to return and scrape text from"}
},
"required": ["query"]
}
}
}
We also need to implement the call_rag_web_browser function, which will be used to retrieve the search data.
def call_rag_web_browser(query: str, max_results: int) -> list[dict]:
"""
Query Google search, scrape the top N pages from the results, and returns their cleaned content as markdown.
First start the Actor and wait for it to finish. Then fetch results from the Actor run's default dataset.
"""
actor_call = apify_client.actor("apify/rag-web-browser").call(run_input={"query": query, "maxResults": max_results})
return apify_client.dataset(actor_call["defaultDatasetId"]).list_items().items
Now, we can create an assistant with the specified instructions and function description:
my_assistant = client.beta.assistants.create(
instructions=INSTRUCTIONS,
name="OpenAI Assistant with Web Browser",
tools=[rag_web_browser_function],
model="gpt-4o-mini",
)
Once the assistant is created, we can initiate a conversation.
Start by creating a thread and adding messages to it, and then calling the run method.
Since runs are asynchronous, we need to continuously poll the Run object until it reaches a terminal status.
To simplify this, we use the create_and_poll convenience function, which both initiates the run and polls it until completion.
thread = client.beta.threads.create()
message = client.beta.threads.messages.create(
thread_id=thread.id, role="user", content="What are the latest LLM news?"
)
run = client.beta.threads.runs.create_and_poll(thread_id=thread.id, assistant_id=my_assistant.id)
Finally, we need to check the run status to determine if the assistant requires any action to retrieve the search data.
If it does, we must submit the results using the submit_tool_outputs function.
This function will trigger RAG Web Browser to fetch the search data and submit it to the assistant for processing.
Let's implement the submit_tool_outputs function:
def submit_tool_outputs(run_):
""" Submit tool outputs to continue the run """
tool_output = []
for tool in run_.required_action.submit_tool_outputs.tool_calls:
if tool.function.name == "call_rag_web_browser":
d = json.loads(tool.function.arguments)
output = call_rag_web_browser(query=d["query"], max_results=d["maxResults"])
tool_output.append(ToolOutput(tool_call_id=tool.id, output=json.dumps(output)))
print("RAG Web Browser added as a tool output.")
return client.beta.threads.runs.submit_tool_outputs_and_poll(thread_id=run_.thread_id, run_id=run_.id, tool_outputs=tool_output)
Now, we can check the run status and submit the tool outputs if required:
if run.status == "requires_action":
run = submit_tool_outputs(run)
The function submit_tool_output also poll the run until it reaches a terminal status.
After the run is completed, we can print the assistant's response:
print("Assistant response:")
for m in client.beta.threads.messages.list(thread_id=run.thread_id):
print(m.content[0].text.value)
For the question "What are the latest LLM news?" the assistant's response might look like this:
Assistant response:
The latest news on LLM is as follows:
- [OpenAI](https://openai.com) has released a new version of GPT-4.
- [Hugging Face](https://huggingface.co) has updated their Transformers library.
- [Apify](https://apify.com) has released a new RAG Web Browser.
Complete example of real-time search data for OpenAI Assistant
import json
from apify_client import ApifyClient
from openai import OpenAI, Stream
from openai.types.beta.threads.run_submit_tool_outputs_params import ToolOutput
client = OpenAI(api_key="YOUR-OPENAI-API-KEY")
apify_client = ApifyClient("YOUR-APIFY-API-TOKEN")
INSTRUCTIONS = """
You are a smart and helpful assistant. Maintain an expert, friendly, and informative tone in your responses.
Your task is to answer questions based on information from the internet.
Always call call_rag_web_browser function to retrieve the latest and most relevant online results.
Never provide answers based solely on your own knowledge.
For each answer, always include relevant sources whenever possible.
"""
rag_web_browser_function = {
"type": "function",
"function": {
"name": "call_rag_web_browser",
"description": "Query Google search, scrape the top N pages from the results, and returns their cleaned content as markdown",
"parameters": {
"type": "object",
"properties": {
"query": {"type": "string", "description": "Use regular search words or enter Google Search URLs. "},
"maxResults": {"type": "integer", "description": "The number of top organic search results to return and scrape text from"}
},
"required": ["query"]
}
}
}
def call_rag_web_browser(query: str, max_results: int) -> list[dict]:
"""
Query Google search, scrape the top N pages from the results, and returns their cleaned content as markdown.
First start the Actor and wait for it to finish. Then fetch results from the Actor run's default dataset.
"""
actor_call = apify_client.actor("apify/rag-web-browser").call(run_input={"query": query, "maxResults": max_results})
return apify_client.dataset(actor_call["defaultDatasetId"]).list_items().items
def submit_tool_outputs(run_):
""" Submit tool outputs to continue the run """
tool_output = []
for tool in run_.required_action.submit_tool_outputs.tool_calls:
if tool.function.name == "call_rag_web_browser":
d = json.loads(tool.function.arguments)
output = call_rag_web_browser(query=d["query"], max_results=d["maxResults"])
tool_output.append(ToolOutput(tool_call_id=tool.id, output=json.dumps(output)))
print("RAG Web Browser added as a tool output.")
return client.beta.threads.runs.submit_tool_outputs_and_poll(thread_id=run_.thread_id, run_id=run_.id, tool_outputs=tool_output)
# Runs are asynchronous, which means you'll want to monitor their status by polling the Run object until a terminal status is reached.
thread = client.beta.threads.create()
message = client.beta.threads.messages.create(
thread_id=thread.id, role="user", content="What are the latest LLM news?"
)
# Run with assistant and poll for the results
run = client.beta.threads.runs.create_and_poll(thread_id=thread.id, assistant_id=my_assistant.id)
if run.status == "requires_action":
run = submit_tool_outputs(run)
print("Assistant response:")
for m in client.beta.threads.messages.list(thread_id=run.thread_id):
print(m.content[0].text.value)
Save data into OpenAI Vector Store and use it in the assistant
To provide real-time or proprietary data, OpenAI Assistants can access the OpenAI Vector Store to retrieve information for their answers. With the Apify OpenAI Vector Store Integration, data saving and updating the OpenAI Vector Store can be fully automated. The following image illustrates the Apify-OpenAI Vector Store integration:
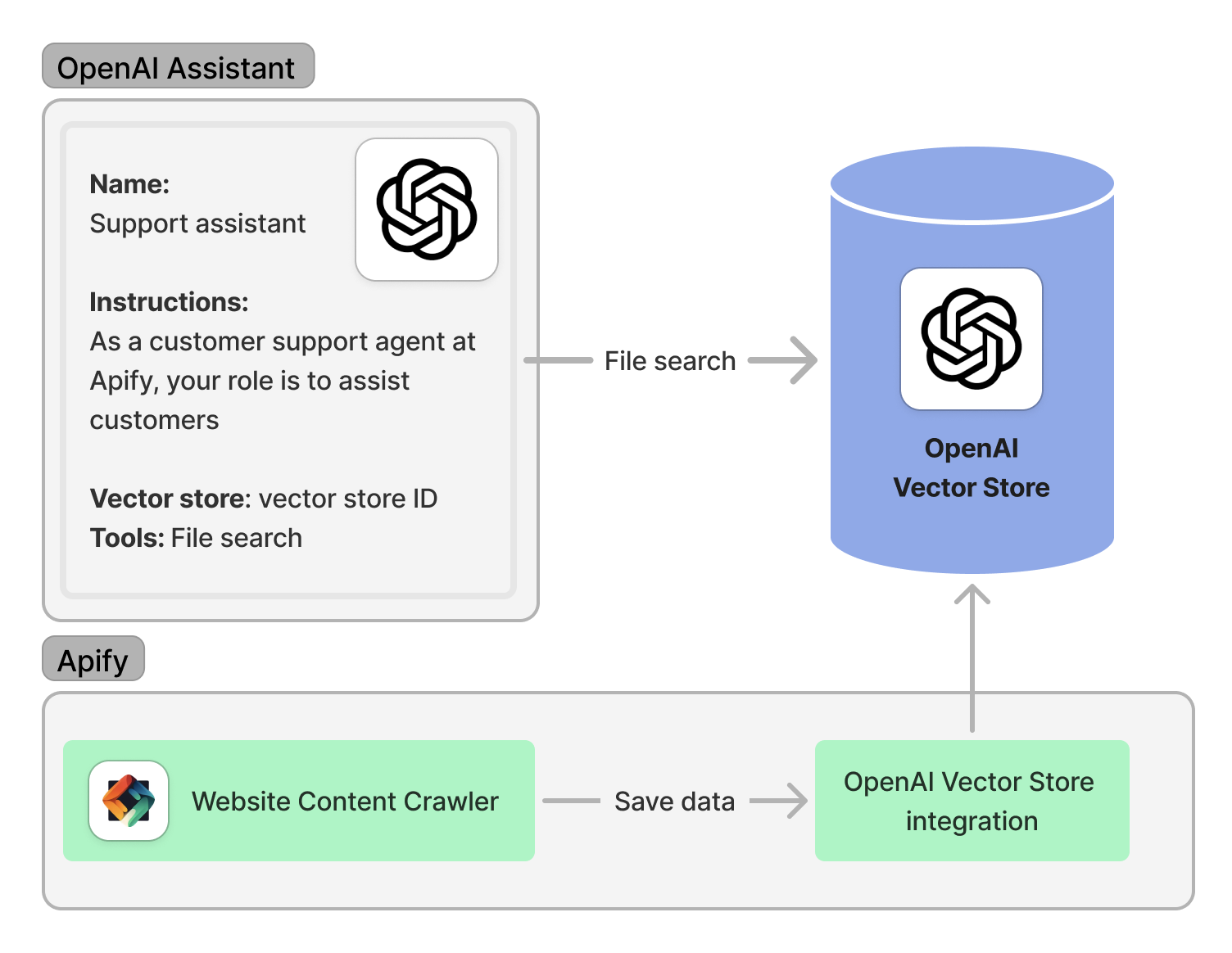
In this example, we'll demonstrate how to save data into the OpenAI Vector Store and use it in the assistant. For more information on automating this process, check out the blog post How we built an AI salesperson with the OpenAI Assistants API.
Before we start, we need to install all dependencies:
pip install apify-client openai
Find your Apify API token and OpenAI API key and initialize OpenAI and Apify clients:
from apify_client import ApifyClient
from openai import OpenAI
client = OpenAI(api_key="YOUR OPENAI API KEY")
apify_client = ApifyClient("YOUR APIFY API TOKEN")
Create an assistant with the instructions and file-search tool:
my_assistant = client.beta.assistants.create(
instructions="As a customer support agent at Apify, your role is to assist customers",
name="Support assistant",
tools=[{"type": "file_search"}],
model="gpt-4o-mini",
)
Next, create a vector store and attach it to the assistant:
vector_store = client.beta.vector_stores.create(name="Support assistant vector store")
assistant = client.beta.assistants.update(
assistant_id=my_assistant.id,
tool_resources={"file_search": {"vector_store_ids": [vector_store.id]}},
)
Now, use Website Content Crawler to crawl the web and save the data into Apify's dataset:
run_input = {"startUrls": [{"url": "https://docs.apify.com/"}], "maxCrawlPages": 10, "crawlerType": "cheerio"}
actor_call_website_crawler = apify_client.actor("apify/website-content-crawler").call(run_input=run_input)
dataset_id = actor_call_website_crawler["defaultDatasetId"]
Finally, save the data into the OpenAI Vector Store using OpenAI Vector Store Integration
run_input_vs = {
"datasetId": dataset_id,
"assistantId": my_assistant.id,
"datasetFields": ["text", "url"],
"openaiApiKey": "YOUR-OPENAI-API-KEY",
"vectorStoreId": vector_store.id,
}
apify_client.actor("jiri.spilka/openai-vector-store-integration").call(run_input=run_input_vs)
Now, the assistant can access the data stored in the OpenAI Vector Store and use it in its responses. Start by creating a thread and adding messages to it. Then, initiate a run and poll for the results. Once the run is completed, you can print the assistant's response.
thread = client.beta.threads.create()
message = client.beta.threads.messages.create(
thread_id=thread.id, role="user", content="How can I scrape a website using Apify?"
)
run = client.beta.threads.runs.create_and_poll(
thread_id=thread.id,
assistant_id=assistant.id,
tool_choice={"type": "file_search"}
)
print("Assistant response:")
for m in client.beta.threads.messages.list(thread_id=run.thread_id):
print(m.content[0].text.value)
For the question "How can I scrape a website using Apify?" the assistant's response might look like this:
Assistant response:
You can scrape a website using Apify by following these steps:
1. Visit the [Apify website](https://apify.com) and create an account.
2. Go to the [Apify Store](https://apify.com/store) and choose a web scraper.
3. Configure the web scraper with the URL of the website you want to scrape.
4. Run the web scraper and download the data.
Complete example of saving data into OpenAI Vector Store and using it in the assistant
from apify_client import ApifyClient
from openai import OpenAI
client = OpenAI(api_key="YOUR-OPENAI-API-KEY")
apify_client = ApifyClient("YOUR-APIFY-API-TOKEN")
my_assistant = client.beta.assistants.create(
instructions="As a customer support agent at Apify, your role is to assist customers",
name="Support assistant",
tools=[{"type": "file_search"}],
model="gpt-4o-mini",
)
# Create a vector store
vector_store = client.beta.vector_stores.create(name="Support assistant vector store")
# Update the assistant to use the new Vector Store
assistant = client.beta.assistants.update(
assistant_id=my_assistant.id,
tool_resources={"file_search": {"vector_store_ids": [vector_store.id]}},
)
run_input = {"startUrls": [{"url": "https://docs.apify.com/"}], "maxCrawlPages": 10, "crawlerType": "cheerio"}
actor_call_website_crawler = apify_client.actor("apify/website-content-crawler").call(run_input=run_input)
dataset_id = actor_call_website_crawler["defaultDatasetId"]
run_input_vs = {
"datasetId": dataset_id,
"assistantId": my_assistant.id,
"datasetFields": ["text", "url"],
"openaiApiKey": "YOUR-OPENAI-API-KEY",
"vectorStoreId": vector_store.id,
}
apify_client.actor("jiri.spilka/openai-vector-store-integration").call(run_input=run_input_vs)
# Create a thread and a message
thread = client.beta.threads.create()
message = client.beta.threads.messages.create(
thread_id=thread.id, role="user", content="How can I scrape a website using Apify?"
)
# Run with assistant and poll for the results
run = client.beta.threads.runs.create_and_poll(
thread_id=thread.id,
assistant_id=assistant.id,
tool_choice={"type": "file_search"}
)
print("Assistant response:")
for m in client.beta.threads.messages.list(thread_id=run.thread_id):
print(m.content[0].text.value)
Related integrations
- ChatGPT integration - Add Apify MCP server as a custom connector in ChatGPT
- OpenAI Agents SDK integration - Integrate Apify MCP server with OpenAI Agents SDK