Usage and resources
Resources
Actors run in Docker containers, which have a limited amount of resources (memory, CPU, disk size, etc). When starting, the Actor needs to be allocated a certain share of those resources, such as CPU capacity that is necessary for the Actor to run.
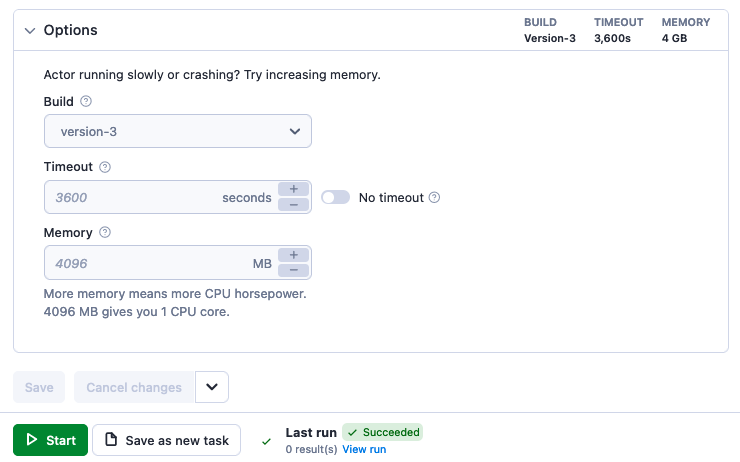
Assigning an Actor a specific Memory capacity, also determines the allocated CPU power and its disk size.
Check out the Limits page for detailed information on Actor memory, CPU limits, disk size and other limits.
Memory
When invoking an Actor, the caller can specify the memory allocation for the Actor run. If not specified, the Actor's default memory is used (which can be dynamic). The memory allocation must follow these requirements:
- It must be a power of 2.
- The minimum allowed value is
128MB - The maximum allowed value is
32768MB - Acceptable values include:
128MB,256MB,512MB,1024MB,2048MB,4096MB,8192MB,16384MB, and32768MB
Additionally, each user has a certain total limit of memory for running Actors. The sum of memory allocated for all running Actors and builds needs to be within this limit, otherwise the user cannot start a new Actor. For more details, see limits.
CPU
The CPU allocation for an Actor is automatically computed based on the assigned memory, following these rules:
- For every
4096MBof memory, the Actor receives one full CPU core - If the memory allocation is not a multiple of
4096MB, the CPU core allocation is calculated proportionally - Examples:
512MB= 1/8 of a CPU core1024MB= 1/4 of a CPU core8192MB= 2 CPU cores
CPU usage spikes
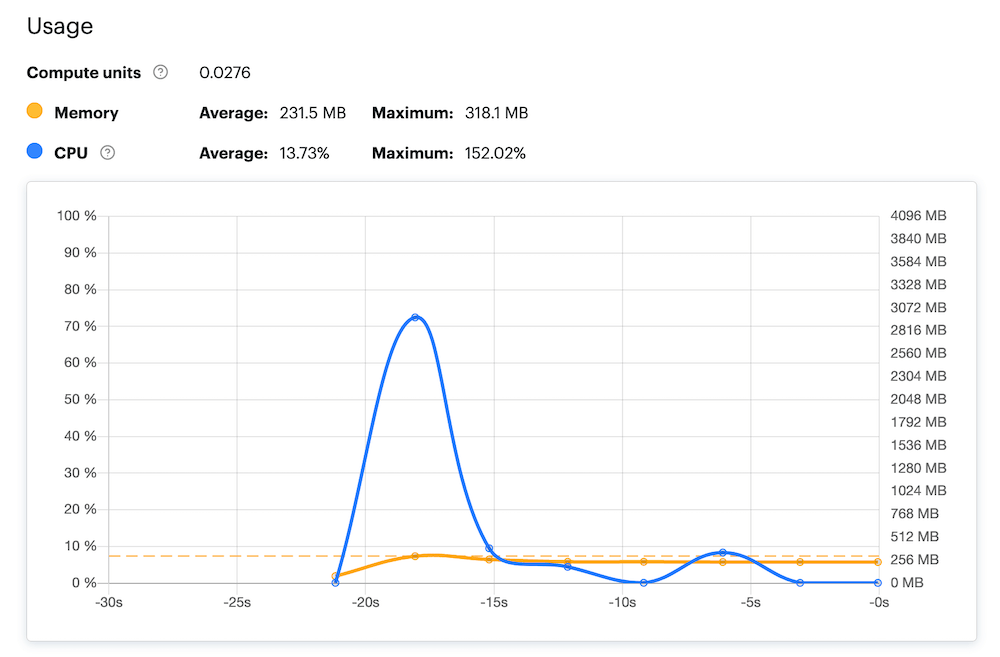
Sometimes, you see the Actor's CPU use go over 100%. This is not unusual. To help an Actor start up faster, it is allocated a free CPU boost. For example, if an Actor is assigned 1GB (25% of a core), it will temporarily be allowed to use 100% of the core, so it gets started quicker.
Disk
The Actor has hard disk space limited by twice the amount of memory. For example, an Actor with 1024MB of memory will have 2048MB of disk available.
Requirements
Actors built with Crawlee use autoscaling. This means that they will always run as efficiently as they can based on the allocated memory. If you double the allocated memory, the run should be twice as fast and consume the same amount of compute units (1 * 1 = 0.5 * 2).
A good middle ground is 4096MB. If you need the results faster, increase the memory (bear in mind the next point, though). You can also try decreasing it to lower the pressure on the target site.
Autoscaling only applies to solutions that run multiple tasks (URLs) for at least 30 seconds. If you need to scrape just one URL or use Actors like Google Sheets that do just a single isolated job, we recommend you lower the memory.
If the Actor doesn't have this information, or you want to use your own solution, just run your solution like you want to use it long term. Let's say that you want to scrape the data every hour for the whole month. You set up a reasonable memory allocation like 4096MB, and the whole run takes 15 minutes. That should consume 1 CU (4 * 0.25 = 1). Now, you just need to multiply that by the number of hours in the day and by the number of days in the month, and you get an estimated usage of 720 (1 * 24 * 30) compute units monthly.
Check out the article on estimating consumption for more details.
Memory requirements
Each use case has its own memory requirements. The larger and more complex your project, the more memory/CPU power it will require. Some examples which have minimum requirements are:
- Actors using Puppeteer or Playwright for real web browser rendering require at least
1024MBof memory. - Large and complex sites like Google Maps require at least
4096MBfor optimal speed and concurrency. - Projects involving large amount of data in memory.
Maximum memory
Apify Actors are most commonly written in Node.js, which uses a single thread process. Unless you use external binaries such as the Chrome browser, Puppeteer, Playwright, or other multi-threaded libraries you will not gain more CPU power from assigning your Actor more than 4096MB of memory because Node.js cannot use more than 1 core.
In other words, giving a Cheerio-based crawler 16384MB of memory (4 CPU cores) will not improve its performance, because these crawlers cannot use more than 1 CPU core.
It's possible to use multiple threads in Node.js-based Actor with some configuration. This can be useful if you need to offload a part of your workload.
Usage
When you run an Actor it generates platform usage that's charged to the user account. Platform usage comprises four main parts:
- Compute units: CPU and memory resources consumed by the Actor.
- Data transfer: The amount of data transferred between the web, Apify platform, and other external systems.
- Proxy costs: Residential or SERP proxy usage.
- Storage operations: Read, write, and other operations performed on the Key-value store, Dataset, and Request queue.
The platform usage can be represented either in raw units (e.g. gigabytes for data transfer, or number of writes for dataset operations), or in the dollar equivalents.
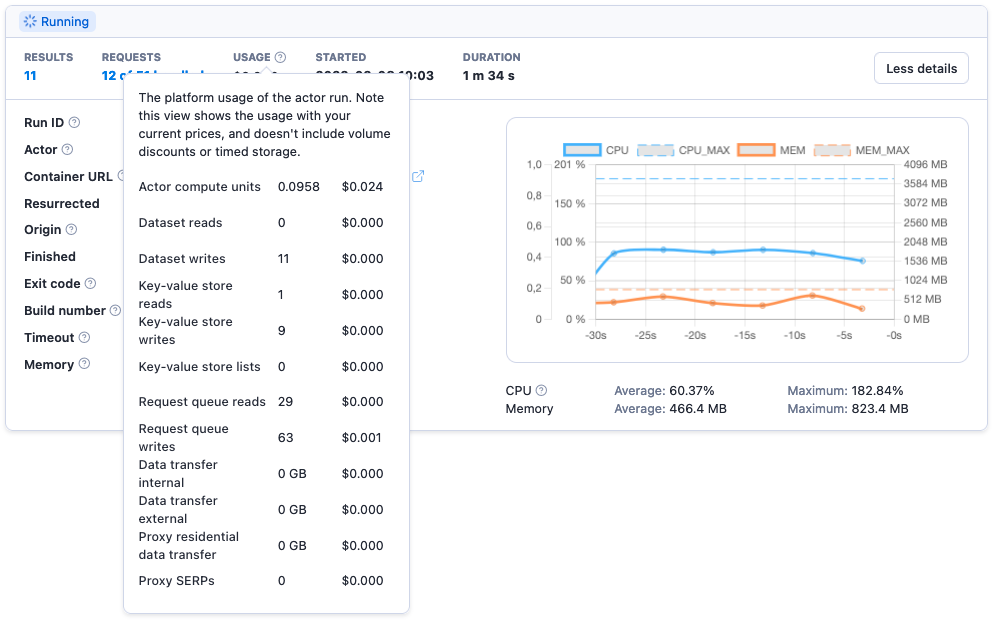
To view the usage of an Actor run, navigate to the Runs section and check out the Usage column.
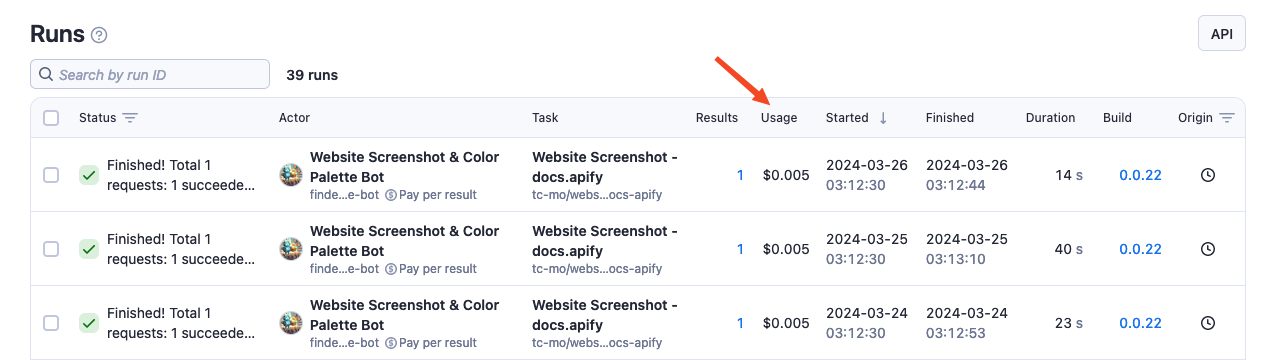
For a more detailed breakdown, click on the specific run you want to examine and then on the ? icon next to the Usage label.
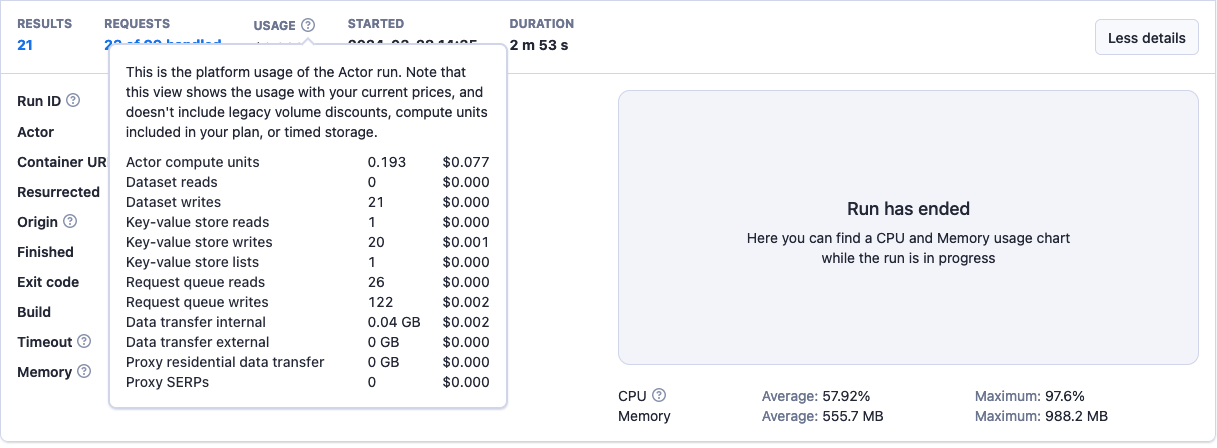
For technical reasons, when viewing the usage in dollars for a specific historical Actor run or build in the API or Apify Console, your current service pricing is used to compute the dollar amount. This should be used for informational purposes only.
For detailed information, FAQ, and, pricing check out the platform pricing page.
What is a compute unit
A compute unit (CU) is the unit of measurement for the resources consumed by Actor runs and builds. You are charged for using Actors based on CU consumption.
For example, running an Actor with1024MB of allocated memory for 1 hour will consume 1 CU. The cost of this CU depends on your subscription plan.
You can check each Actor run's exact CU usage in the run's details.
You can find a summary of your overall platform and CU usage in the Billing section of Apify Console.
Compute unit calculation
CUs are calculated by multiplying two factors:
- Memory (MB) - The size of the allocated server for your Actor or task run.
- Duration (hours) - The duration for which the server is used (Actor or task run). For example, if your run took 6 minutes, you would use 0.1 (hours) as the second number to calculate CUs. The minimum granularity is a second.
Example: 1024MB memory x 1 hour = 1 CU
What determines consumption
The factors that influence resource consumption, in order of importance, are:
-
Browser vs. Plain HTTP: Launching a browser (e.g., Puppeteer/Playwright) is resource-intensive and slower compared to working with plain HTML (Cheerio). Using Cheerio can be up to 20 times faster.
-
Run size and frequency: Large runs can use full resource scaling and are not subjected to repeated Actor start-ups (as opposed to many short runs). Whenever possible, opt for larger batches.
-
Page type: Heavy pages, such as Amazon or Facebook will take more time to load regardless whether you use a browser or Cheerio. Large pages can take up to 3 times more resources to load and parse than average pages.
You can check out our article on estimating consumption for more details on what determines consumption.