Inspecting web pages with browser DevTools
In this lesson we'll use the browser tools for developers to inspect and manipulate the structure of a website.
A browser is the most complete tool for navigating websites. Scrapers are like automated browsers - and sometimes, they actually are automated browsers. The key difference? There's no user to decide where to go or eyes to see what's displayed. Everything has to be pre-programmed.
All modern browsers provide developer tools, or DevTools, for website developers to debug their work. We'll use them to understand how websites are structured and identify the behavior our scraper needs to mimic. Here's the typical workflow for creating a scraper:
- Inspect the target website in DevTools to understand its structure and determine how to extract the required data.
- Translate those findings into code.
- If the scraper fails due to overlooked edge cases or, over time, due to website changes, go back to step 1.
Now let's spend some time figuring out what the detective work in step 1 is about.
Opening DevTools
Google Chrome is currently the most popular browser, and many others use the same core. That's why we'll focus on Chrome DevTools here. However, the steps are similar in other browsers, as Safari has its Web Inspector and Firefox also has DevTools.
Now let's peek behind the scenes of a real-world website - say, Wikipedia. We'll open Google Chrome and visit wikipedia.org. Then, let's press F12, or right-click anywhere on the page and select Inspect.
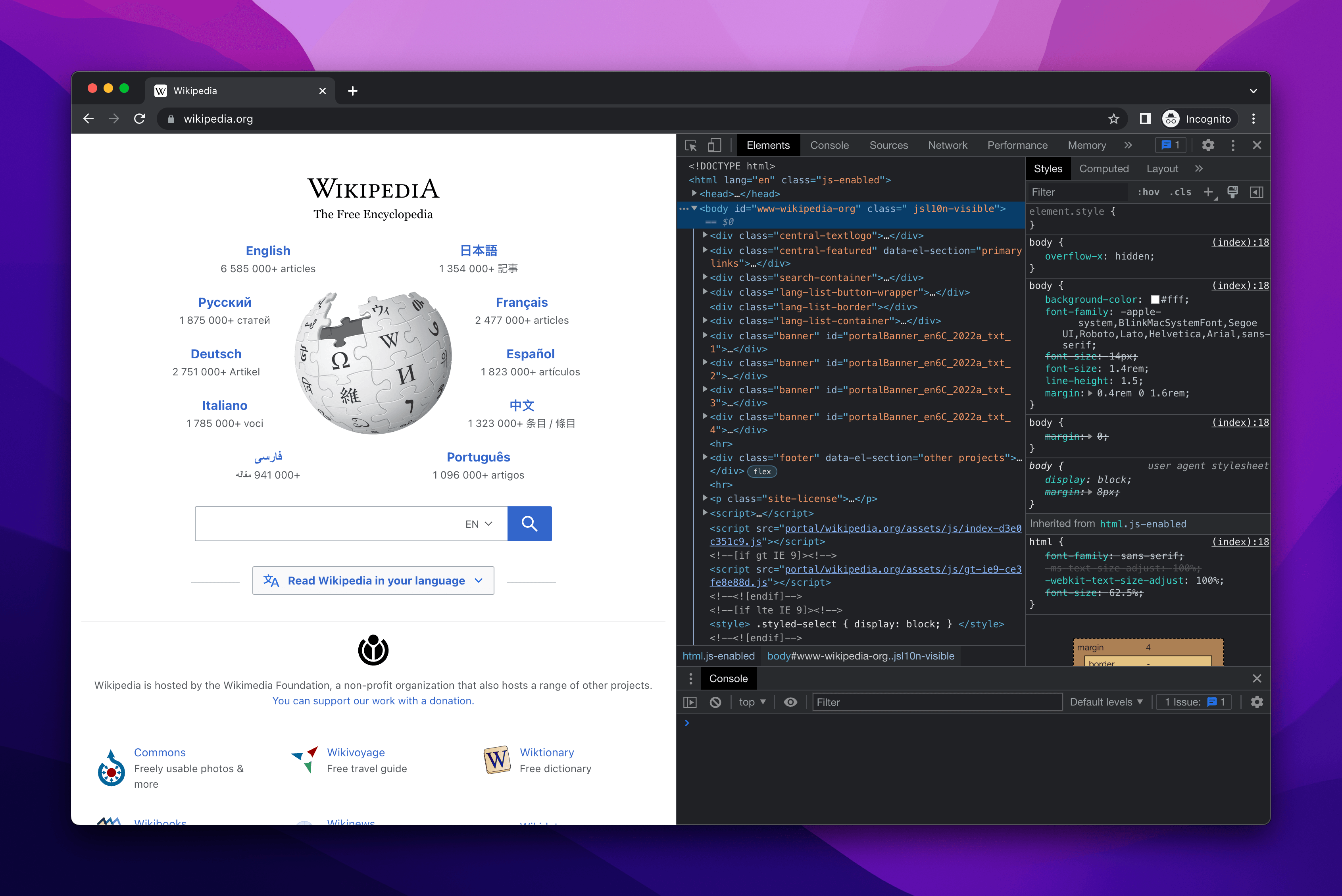
Websites are built with three main technologies: HTML, CSS, and JavaScript. In the Elements tab, DevTools shows the HTML and CSS of the current page:
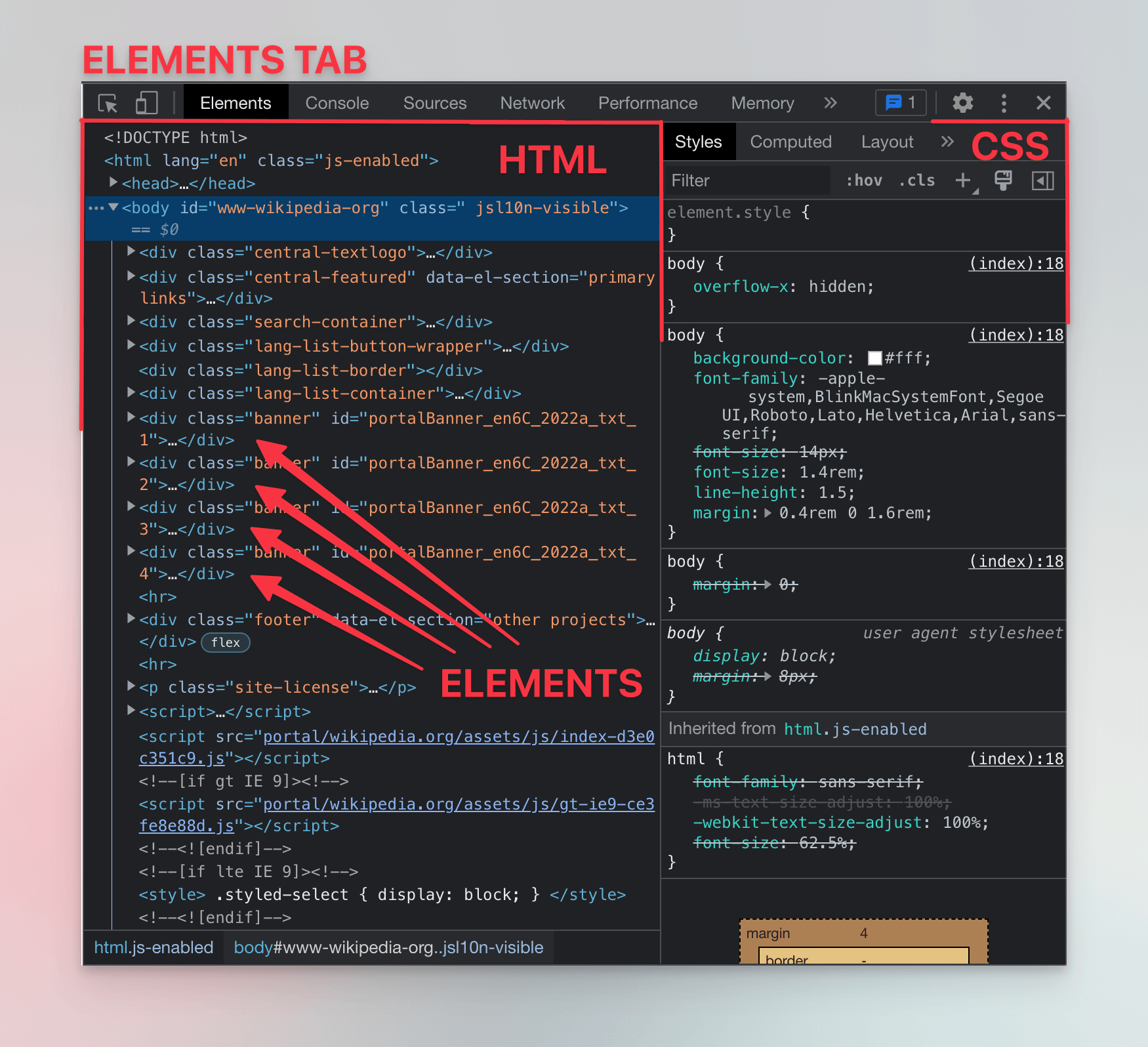
DevTools may appear differently depending on your screen size. For instance, on smaller screens, the CSS panel might move below the HTML elements panel instead of appearing in the right pane.
Think of HTML elements as the frame that defines a page's structure. A basic HTML element includes an opening tag, a closing tag, and attributes. Here's an article element with an id attribute. It wraps h1 and p elements, both containing text. Some text is emphasized using em.
<article id="article-123">
<h1 class="heading">First Level Heading</h1>
<p>Paragraph with <em>emphasized text</em>.</p>
</article>
HTML, a markup language, describes how everything on a page is organized, how elements relate to each other, and what they mean. It doesn't define how elements should look - that's where CSS comes in. CSS is like the velvet covering the frame. Using styles, we can select elements and assign rules that tell the browser how they should appear. For instance, we can style all elements with heading in their class attribute to make the text blue and uppercase.
.heading {
color: blue;
text-transform: uppercase;
}
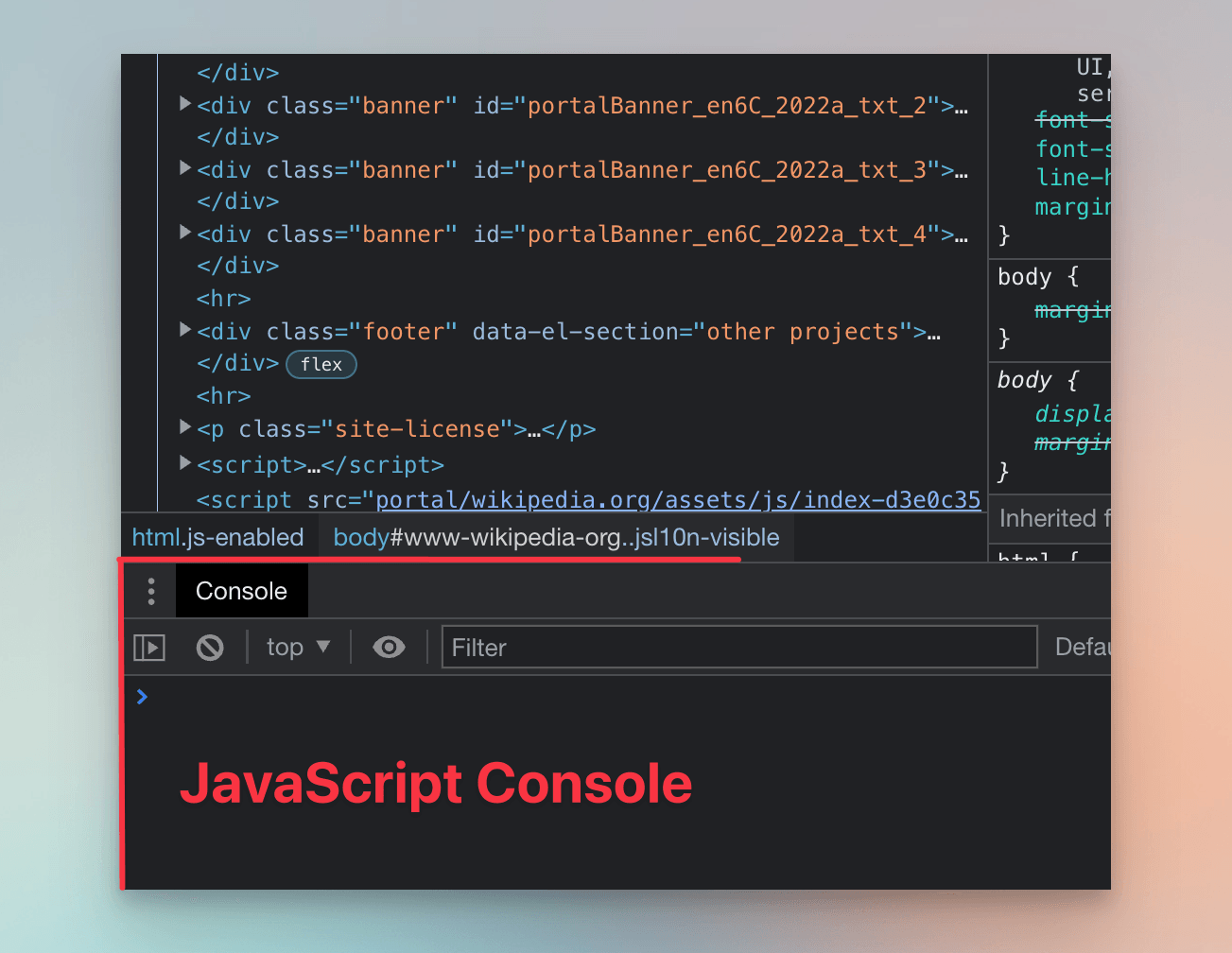
While HTML and CSS describe what the browser should display, JavaScript adds interaction to the page. In DevTools, the Console tab allows ad-hoc experimenting with JavaScript.
If you don't see it, press ESC to toggle the Console. Running commands in the Console lets us manipulate the loaded page - we’ll try this shortly.
Selecting an element
In the top-left corner of DevTools, let's find the icon with an arrow pointing to a square.
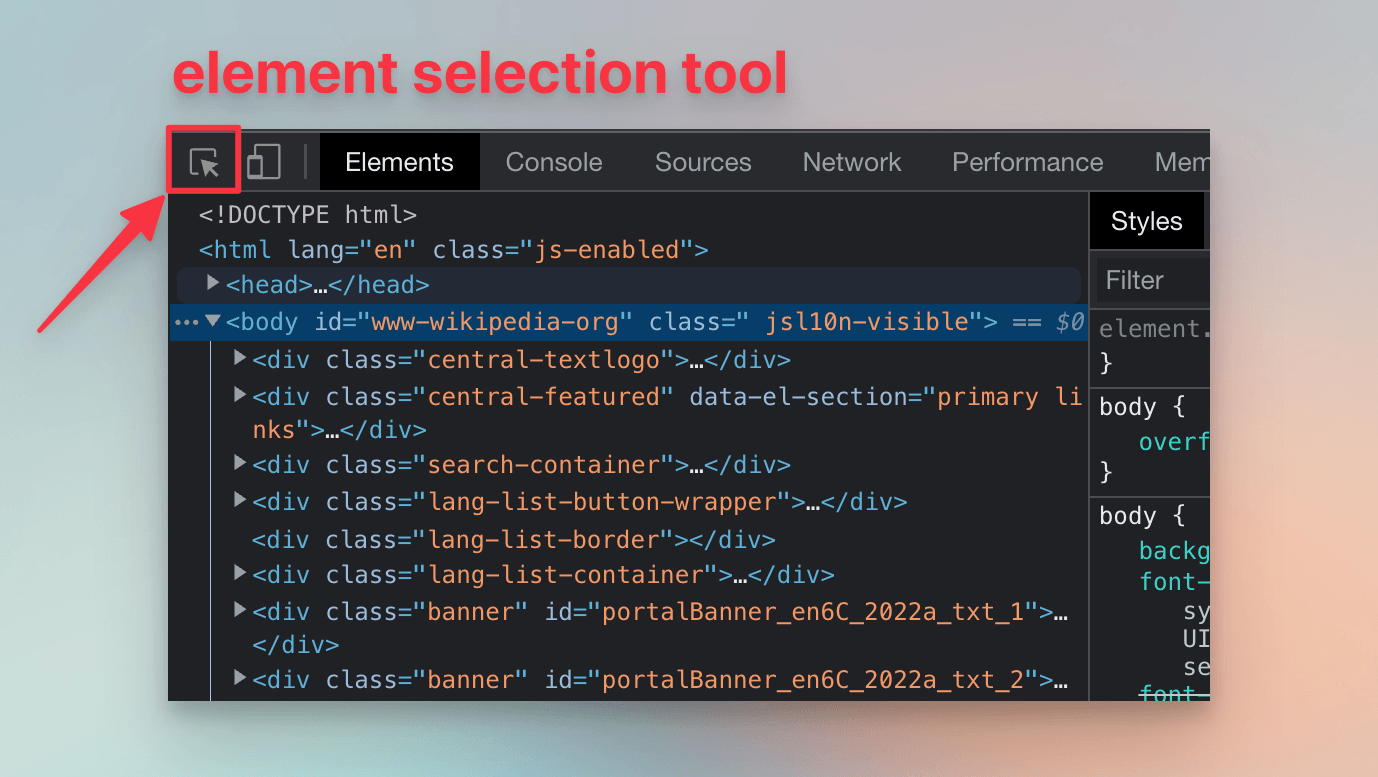
We'll click the icon and hover your cursor over Wikipedia's subtitle, The Free Encyclopedia. As we move our cursor, DevTools will display information about the HTML element under it. We'll click on the subtitle. In the Elements tab, DevTools will highlight the HTML element that represents the subtitle.
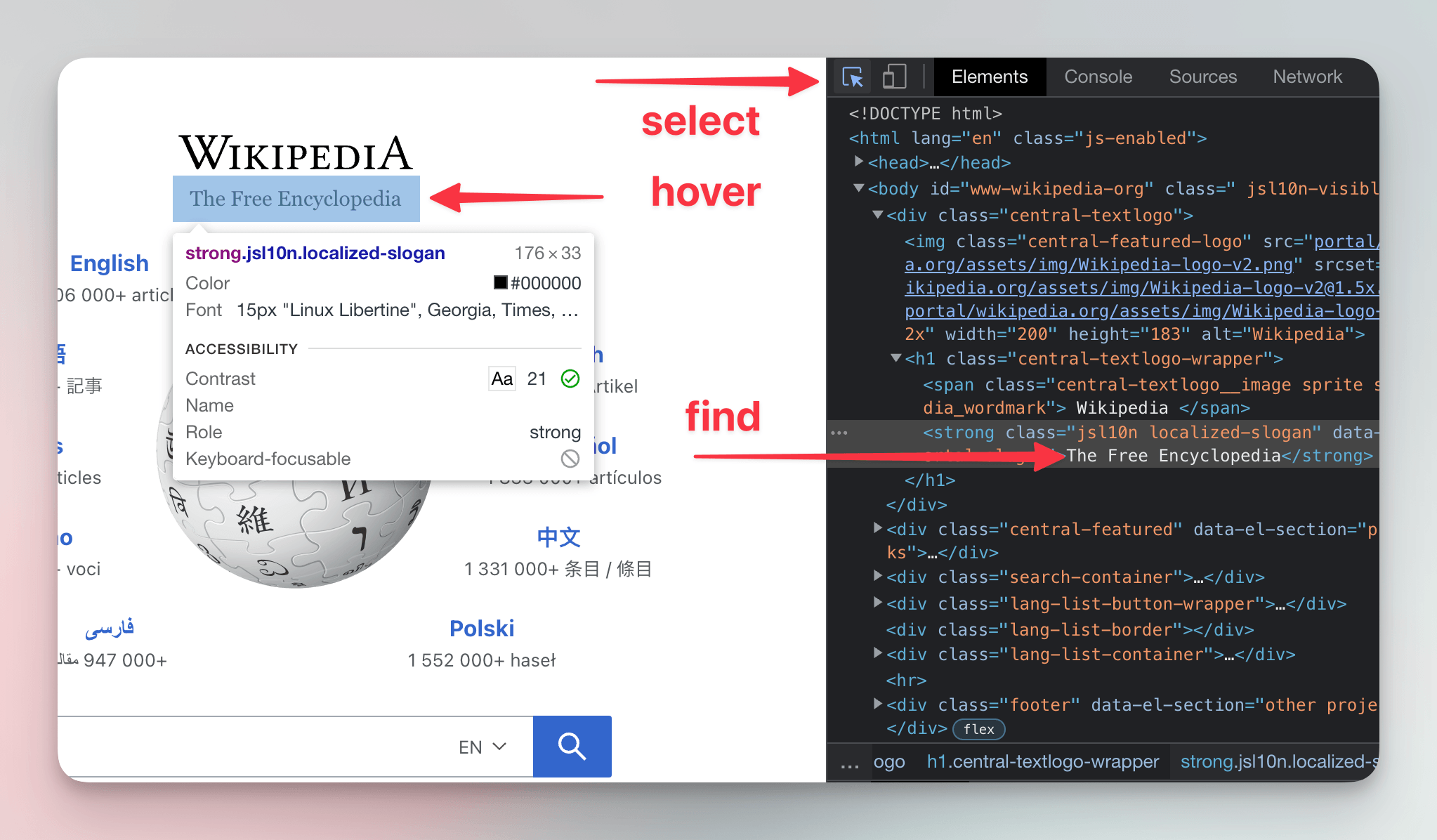
The highlighted section should look something like this:
<strong class="jsl10n localized-slogan" data-jsl10n="portal.slogan">
The Free Encyclopedia
</strong>
If we were experienced creators of scrapers, our eyes would immediately spot what's needed to make a program that fetches Wikipedia's subtitle. The program would need to download the page's source code, find a strong element with localized-slogan in its class attribute, and extract its text.
In HTML, whitespace isn't significant, i.e., it only makes the code readable. The following code snippets are equivalent:
<strong>
The Free Encyclopedia
</strong>
<strong>The Free
Encyclopedia
</strong>
Interacting with an element
We won't be creating Node.js scrapers just yet. Let's first get familiar with what we can do in the DevTools console and how we can further interact with HTML elements on the page.
In the Elements tab, with the subtitle element highlighted, let's right-click the element to open the context menu. There, we'll choose Store as global variable. The Console should appear, with a temp1 variable ready.
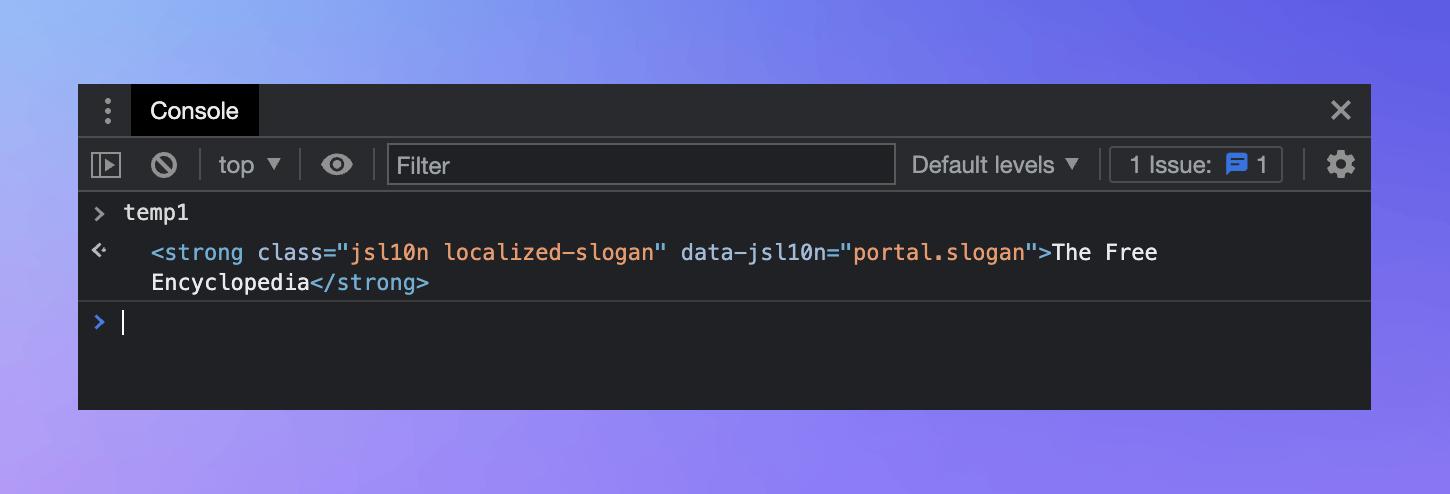
The Console allows us to run code in the context of the loaded page. We can use it to play around with elements.
For a start, let's access some of the subtitle's properties. One such property is textContent, which contains the text inside the HTML element. The last line in the Console is where your cursor is. We'll type the following and hit Enter:
temp1.textContent;
The result should be 'The Free Encyclopedia'. Now let's try this:
temp1.outerHTML;
This should return the element's HTML tag as a string. Finally, we'll run the next line to change the text of the element:
temp1.textContent = 'Hello World!';
When we change elements in the Console, those changes reflect immediately on the page!
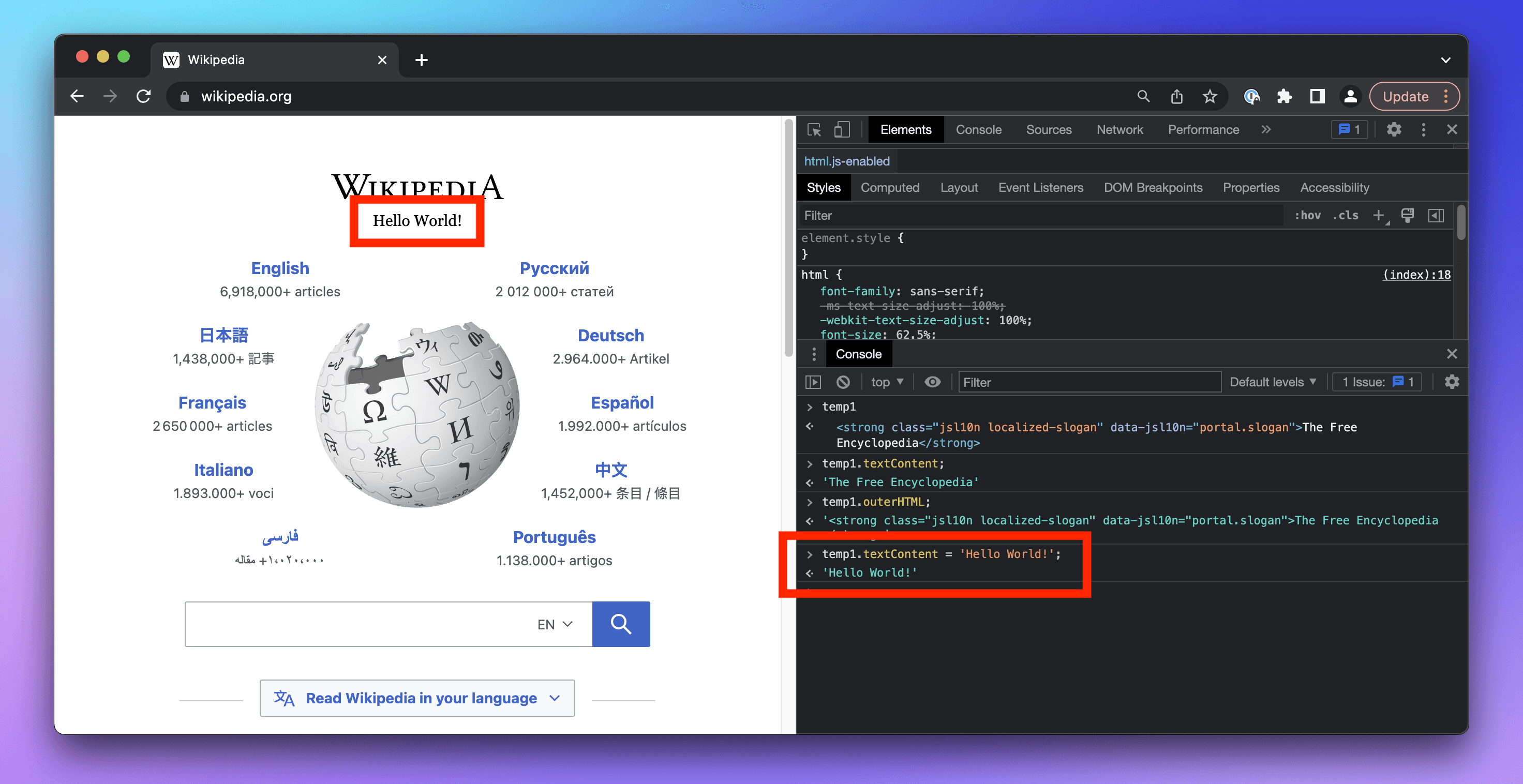
But don't worry - we haven't hacked Wikipedia. The change only happens in our browser. If we reload the page, the change will disappear. This, however, is an easy way to craft a screenshot with fake content. That's why screenshots shouldn't be trusted as evidence.
We're not here for playing around with elements, though - we want to create a scraper for an e-commerce website to watch prices. In the next lesson, we'll examine the website and use CSS selectors to locate HTML elements containing the data we need.
Exercises
These challenges are here to help you test what you’ve learned in this lesson. Try to resist the urge to peek at the solutions right away. Remember, the best learning happens when you dive in and do it yourself!
You're about to touch the real web, which is practical and exciting! But websites change, so some exercises might break. If you run into any issues, please leave a comment below or file a GitHub Issue.
Find FIFA logo
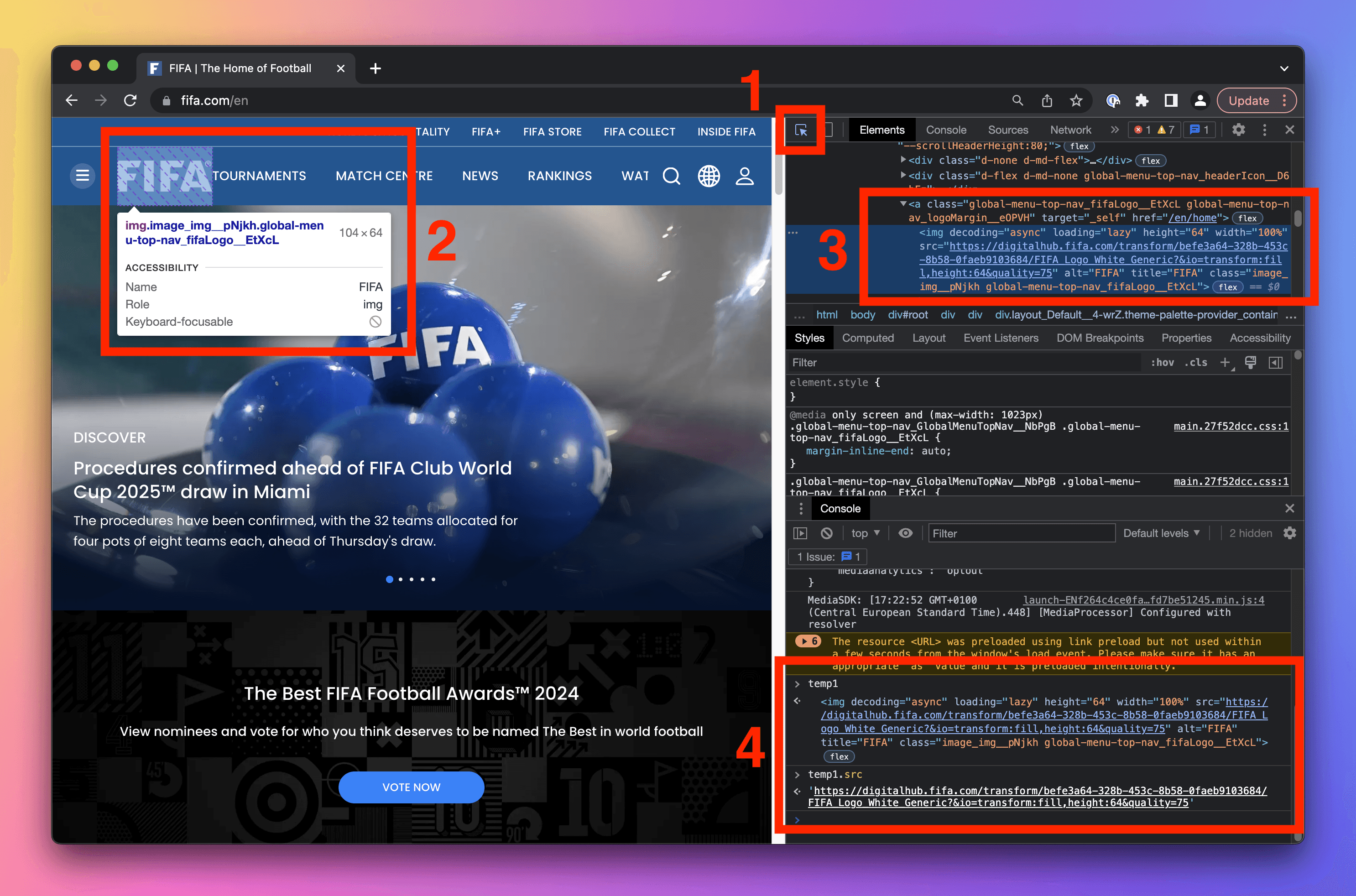
Open the FIFA website and use the DevTools to figure out the URL of FIFA's logo image file.
You're looking for an img element with a src attribute.
Solution
- Go to fifa.com.
- Activate the element selection tool.
- Click on the logo.
- Send the highlighted element to the Console using the Store as global variable option from the context menu.
- In the console, type
temp1.srcand hit Enter.
Make your own news
Open a news website, such as CNN. Use the Console to change the headings of some articles.
Solution
- Go to cnn.com.
- Activate the element selection tool.
- Click on a heading.
- Send the highlighted element to the Console using the Store as global variable option from the context menu.
- In the console, type
temp1.textContent = 'Something something'and hit Enter.