Getting links from HTML with Node.js
In this lesson, we'll locate and extract links to individual product pages. We'll use Cheerio to find the relevant bits of HTML.
The previous lesson concludes our effort to create a scraper. Our program now downloads HTML, locates and extracts data from the markup, and saves the data in a structured and reusable way.
For some use cases, this is already enough! In other cases, though, scraping just one page is hardly useful. The data is spread across the website, over several pages.
Crawling websites
We'll use a technique called crawling, i.e. following links to scrape multiple pages. The algorithm goes like this:
- Visit the start URL.
- Extract new URLs (and data), and save them.
- Visit one of the newly found URLs and save data and/or more URLs from it.
- Repeat steps 2 and 3 until you have everything you need.
This will help us figure out the actual prices of products, as right now, for some, we're only getting the min price. Implementing the algorithm will require quite a few changes to our code, though.
Restructuring code
Over the course of the previous lessons, the code of our program grew to almost 50 lines containing downloading, parsing, and exporting:
import * as cheerio from 'cheerio';
import { writeFile } from 'fs/promises';
import { AsyncParser } from '@json2csv/node';
const url = "https://warehouse-theme-metal.myshopify.com/collections/sales";
const response = await fetch(url);
if (response.ok) {
const html = await response.text();
const $ = cheerio.load(html);
const data = $(".product-item").toArray().map(element => {
const $productItem = $(element);
const $title = $productItem.find(".product-item__title");
const title = $title.text().trim();
const $price = $productItem.find(".price").contents().last();
const priceRange = { minPrice: null, price: null };
const priceText = $price
.text()
.trim()
.replace("$", "")
.replace(".", "")
.replace(",", "");
if (priceText.startsWith("From ")) {
priceRange.minPrice = parseInt(priceText.replace("From ", ""));
} else {
priceRange.minPrice = parseInt(priceText);
priceRange.price = priceRange.minPrice;
}
return { title, ...priceRange };
});
const jsonData = JSON.stringify(data);
await writeFile('products.json', jsonData);
const parser = new AsyncParser();
const csvData = await parser.parse(data).promise();
await writeFile('products.csv', csvData);
} else {
throw new Error(`HTTP ${response.status}`);
}
Let's introduce several functions to make the whole thing easier to digest. First, we can turn the beginning of our program into this download() function, which takes a URL and returns a Cheerio object:
async function download(url) {
const response = await fetch(url);
if (response.ok) {
const html = await response.text();
return cheerio.load(html);
} else {
throw new Error(`HTTP ${response.status}`);
}
}
Next, we can put parsing into a parseProduct() function, which takes the product item element and returns the object with data:
function parseProduct($productItem) {
const $title = $productItem.find(".product-item__title");
const title = $title.text().trim();
const $price = $productItem.find(".price").contents().last();
const priceRange = { minPrice: null, price: null };
const priceText = $price
.text()
.trim()
.replace("$", "")
.replace(".", "")
.replace(",", "");
if (priceText.startsWith("From ")) {
priceRange.minPrice = parseInt(priceText.replace("From ", ""));
} else {
priceRange.minPrice = parseInt(priceText);
priceRange.price = priceRange.minPrice;
}
return { title, ...priceRange };
}
Now the JSON export. For better readability, let's make a small change here and set the indentation level to two spaces:
function exportJSON(data) {
return JSON.stringify(data, null, 2);
}
The last function we'll add will take care of the CSV export:
async function exportCSV(data) {
const parser = new AsyncParser();
return await parser.parse(data).promise();
}
Now let's put it all together:
import * as cheerio from 'cheerio';
import { writeFile } from 'fs/promises';
import { AsyncParser } from '@json2csv/node';
async function download(url) {
const response = await fetch(url);
if (response.ok) {
const html = await response.text();
return cheerio.load(html);
} else {
throw new Error(`HTTP ${response.status}`);
}
}
function parseProduct($productItem) {
const $title = $productItem.find(".product-item__title");
const title = $title.text().trim();
const $price = $productItem.find(".price").contents().last();
const priceRange = { minPrice: null, price: null };
const priceText = $price
.text()
.trim()
.replace("$", "")
.replace(".", "")
.replace(",", "");
if (priceText.startsWith("From ")) {
priceRange.minPrice = parseInt(priceText.replace("From ", ""));
} else {
priceRange.minPrice = parseInt(priceText);
priceRange.price = priceRange.minPrice;
}
return { title, ...priceRange };
}
function exportJSON(data) {
return JSON.stringify(data, null, 2);
}
async function exportCSV(data) {
const parser = new AsyncParser();
return await parser.parse(data).promise();
}
const listingURL = "https://warehouse-theme-metal.myshopify.com/collections/sales";
const $ = await download(listingURL);
const data = $(".product-item").toArray().map(element => {
const $productItem = $(element);
const item = parseProduct($productItem);
return item;
});
await writeFile('products.json', exportJSON(data));
await writeFile('products.csv', await exportCSV(data));
The program is much easier to read now. With the parseProduct() function handy, we could also replace the convoluted loop with one that only takes up five lines of code.
We turned the whole program upside down, and at the same time, we didn't make any actual changes! This is refactoring: improving the structure of existing code without changing its behavior.

Extracting links
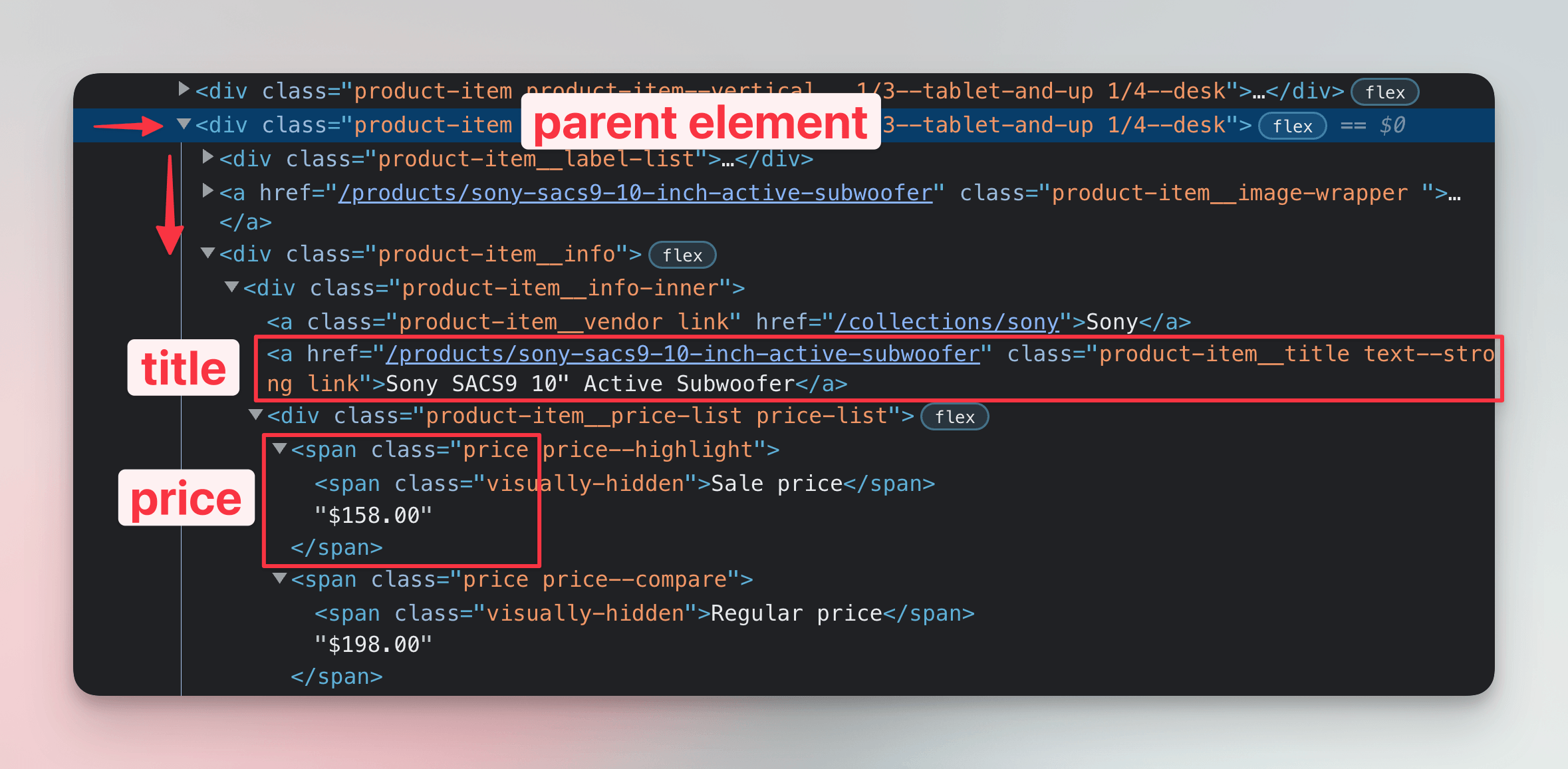
With everything in place, we can now start working on a scraper that also scrapes the product pages. For that, we'll need the links to those pages. Let's open the browser DevTools and remind ourselves of the structure of a single product item:
Several methods exist for transitioning from one page to another, but the most common is a link element, which looks like this:
<a href="https://example.com">Text of the link</a>
In DevTools, we can see that each product title is, in fact, also a link element. We already locate the titles, so that makes our task easier. We just need to edit the code so that it extracts not only the text of the element but also the href attribute. Cheerio selections support accessing attributes using the .attr() method:
function parseProduct($productItem) {
const $title = $productItem.find(".product-item__title");
const title = $title.text().trim();
const url = $title.attr("href");
...
return { url, title, ...priceRange };
}
In the previous code example, we've also added the URL to the object returned by the function. If we run the scraper now, it should produce exports where each product contains a link to its product page:
[
{
"url": "/products/jbl-flip-4-waterproof-portable-bluetooth-speaker",
"title": "JBL Flip 4 Waterproof Portable Bluetooth Speaker",
"minPrice": 7495,
"price": 7495
},
{
"url": "/products/sony-xbr-65x950g-65-class-64-5-diag-bravia-4k-hdr-ultra-hd-tv",
"title": "Sony XBR-950G BRAVIA 4K HDR Ultra HD TV",
"minPrice": 139800,
"price": null
},
...
]
Hmm, but that isn't what we wanted! Where is the beginning of each URL? It turns out the HTML contains so-called relative links.
Turning relative links into absolute
Browsers reading the HTML know the base address and automatically resolve such links, but we'll have to do this manually. The built-in URL object will help us.
We'll change the parseProduct() function so that it also takes the base URL as an argument and then joins it with the relative URL to the product page:
function parseProduct($productItem, baseURL) {
const $title = $productItem.find(".product-item__title");
const title = $title.text().trim();
const url = new URL($title.attr("href"), baseURL).href;
...
return { url, title, ...priceRange };
}
Now we'll pass the base URL to the function in the main body of our program:
const listingURL = "https://warehouse-theme-metal.myshopify.com/collections/sales";
const $ = await download(listingURL);
const data = $(".product-item").toArray().map(element => {
const $productItem = $(element);
const item = parseProduct($productItem, listingURL);
return item;
});
When we run the scraper now, we should see full URLs in our exports:
[
{
"url": "https://warehouse-theme-metal.myshopify.com/products/jbl-flip-4-waterproof-portable-bluetooth-speaker",
"title": "JBL Flip 4 Waterproof Portable Bluetooth Speaker",
"minPrice": 7495,
"price": 7495
},
{
"url": "https://warehouse-theme-metal.myshopify.com/products/sony-xbr-65x950g-65-class-64-5-diag-bravia-4k-hdr-ultra-hd-tv",
"title": "Sony XBR-950G BRAVIA 4K HDR Ultra HD TV",
"minPrice": 139800,
"price": null
},
...
]
Ta-da! We've managed to get links leading to the product pages. In the next lesson, we'll crawl these URLs so that we can gather more details about the products in our dataset.
Exercises
These challenges are here to help you test what you’ve learned in this lesson. Try to resist the urge to peek at the solutions right away. Remember, the best learning happens when you dive in and do it yourself!
You're about to touch the real web, which is practical and exciting! But websites change, so some exercises might break. If you run into any issues, please leave a comment below or file a GitHub Issue.
Scrape links to top tennis players
Download the WTA singles rankings page, use Cheerio to parse it, and print links to the detail pages of the listed players. Start with this URL:
https://www.wtatennis.com/rankings/singles
Your program should print the following:
https://www.wtatennis.com/players/318310/iga-swiatek
https://www.wtatennis.com/players/322341/aryna-sabalenka
https://www.wtatennis.com/players/326911/coco-gauff
https://www.wtatennis.com/players/320203/elena-rybakina
...
Solution
import * as cheerio from 'cheerio';
const listingUrl = 'https://www.wtatennis.com/rankings/singles';
const response = await fetch(listingUrl);
if (!response.ok) {
throw new Error(`HTTP ${response.status}`);
}
const html = await response.text();
const $ = cheerio.load(html);
for (const element of $('.rankings__list .player-row-drawer__link').toArray()) {
const playerUrlRelative = $(element).attr('href');
const playerUrl = new URL(playerUrlRelative, listingUrl).href;
console.log(playerUrl);
}
Scrape links to F1 news
Download Guardian's page with the latest F1 news, use Cheerio to parse it, and print links to all the listed articles. Start with this URL:
https://www.theguardian.com/sport/formulaone
Your program should print something like the following:
https://www.theguardian.com/world/2024/sep/13/africa-f1-formula-one-fans-lewis-hamilton-grand-prix
https://www.theguardian.com/sport/2024/sep/12/mclaren-lando-norris-oscar-piastri-team-orders-f1-title-race-max-verstappen
https://www.theguardian.com/sport/article/2024/sep/10/f1-designer-adrian-newey-signs-aston-martin-deal-after-quitting-red-bull
https://www.theguardian.com/sport/article/2024/sep/02/max-verstappen-damns-his-undriveable-monster-how-bad-really-is-it-and-why
...
Solution
import * as cheerio from 'cheerio';
const listingUrl = 'https://www.theguardian.com/sport/formulaone';
const response = await fetch(listingUrl);
if (!response.ok) {
throw new Error(`HTTP ${response.status}`);
}
const html = await response.text();
const $ = cheerio.load(html);
for (const element of $('#maincontent ul li').toArray()) {
const $item = $(element);
const $link = $item.find('a').first();
if ($link.length) {
const url = new URL($link.attr('href'), listingUrl).href;
console.log(url);
}
}
Note that some cards contain two links. One leads to the article, and one to the comments. If we selected all the links in the list by #maincontent ul li a, we would get incorrect output like this:
https://www.theguardian.com/sport/article/2024/sep/02/example
https://www.theguardian.com/sport/article/2024/sep/02/example#comments