Using a scraping framework with Node.js
In this lesson, we'll rework our application for watching prices so that it builds on top of a scraping framework. We'll use Crawlee to make the program simpler, faster, and more robust.
Before rewriting our code, let's point out several caveats in our current solution:
- Hard to maintain: All the data we need from the listing page is also available on the product page. By scraping both, we have to maintain selectors for two HTML documents. Instead, we could scrape links from the listing page and process all data on the product pages.
- Inconsiderate: The program sends all requests in parallel, which is efficient but inconsiderate to the target website and may result in us getting blocked.
- No logging: The scraper gives no sense of progress, making it tedious to use. Debugging issues becomes even more frustrating without proper logs.
- Boilerplate code: We implement downloading and parsing HTML, or exporting data to CSV, although we're not the first people to meet and solve these problems.
- Prone to anti-scraping: If the target website implemented anti-scraping measures, a bare-bones program like ours would stop working.
- Browser means rewrite: We got lucky extracting variants. If the website didn't include a fallback, we might have had no choice but to spin up a browser instance and automate clicking on buttons. Such a change in the underlying technology would require a complete rewrite of our program.
- No error handling: The scraper stops if it encounters issues. It should allow for skipping problematic products with warnings or retrying downloads when the website returns temporary errors.
In this lesson, we'll address all of the above issues while keeping the code concise with the help of a scraping framework. We'll use Crawlee, not just because we created it, but because it's the most popular JavaScript framework for web scraping.
Starting with Crawlee
First let's install the Crawlee package. The framework has a lot of dependencies, so expect the installation to take a while.
$ npm install crawlee --save
added 123 packages, and audited 123 packages in 0s
...
Now let's use the framework to create a new version of our scraper. First, let's rename the index.js file to oldindex.js, so that we can keep peeking at the original implementation while working on the new one. Then, in the same project directory, we'll create a new, empty index.js. The initial content will look like this:
import { CheerioCrawler } from 'crawlee';
const crawler = new CheerioCrawler();
crawler.router.addDefaultHandler(async ({ $, log }) => {
const title = $('title').text().trim();
log.info(title);
});
await crawler.run(['https://warehouse-theme-metal.myshopify.com/collections/sales']);
In the code, we do the following:
- Import the necessary module.
- Create a crawler object, which manages the scraping process. In this case, it's a
CheerioCrawler, which requests HTML from websites and parses it with Cheerio. Other crawlers, such asPlaywrightCrawler, would be suitable if we wanted to scrape by automating a real browser. - Define an asynchronous function as a default request handler. It receives a context object with Cheerio's
$instance and a logger. - Extract the page title and log it.
- Run the crawler on a product listing URL and await its completion.
Let's see what it does when we run it:
$ node index.js
INFO CheerioCrawler: Starting the crawler.
INFO CheerioCrawler: Sales
INFO CheerioCrawler: All requests from the queue have been processed, the crawler will shut down.
INFO CheerioCrawler: Final request statistics: {"requestsFinished":1,"requestsFailed":0,"retryHistogram":[1],"requestAvgFailedDurationMillis":null,"requestAvgFinishedDurationMillis":388,"requestsFinishedPerMinute":131,"requestsFailedPerMinute":0,"requestTotalDurationMillis":388,"requestsTotal":1,"crawlerRuntimeMillis":458}
INFO CheerioCrawler: Finished! Total 1 requests: 1 succeeded, 0 failed. {"terminal":true}
If our previous scraper didn't give us any sense of progress, Crawlee feeds us with perhaps too much information for the purposes of a small program. Among all the logging, notice the line with Sales. That's the page title! We managed to create a Crawlee scraper that downloads the product listing page, parses it with Cheerio, extracts the title, and prints it.
Crawling product detail pages
The code is now less accessible to beginners, and the size of the program is about the same as if we worked without a framework. The tradeoff of using a framework is that primitive scenarios may become unnecessarily complex, while complex scenarios may become surprisingly primitive. As we rewrite the rest of the program, the benefits of using Crawlee will become more apparent.
For example, it takes only a few changes to the code to extract and follow links to all the product detail pages:
import { CheerioCrawler } from 'crawlee';
const crawler = new CheerioCrawler();
crawler.router.addDefaultHandler(async ({ enqueueLinks }) => {
await enqueueLinks({ label: 'DETAIL', selector: '.product-list a.product-item__title' });
});
crawler.router.addHandler('DETAIL', async ({ request, log }) => {
log.info(request.url);
});
await crawler.run(['https://warehouse-theme-metal.myshopify.com/collections/sales']);
First, it's necessary to inspect the page in browser DevTools to figure out the CSS selector that allows us to locate links to all the product detail pages. Then we can use the enqueueLinks() method to find the links and add them to Crawlee's internal HTTP request queue. We tell the method to label all the requests as DETAIL.
Crawlee routes each request to the right function based on the request label. The default handler processes listing pages, and the DETAIL handler logs product URLs.
If we run the code, we should see how Crawlee first downloads the listing page and then makes parallel requests to each of the detail pages, logging their URLs along the way:
$ node index.js
INFO CheerioCrawler: Starting the crawler.
INFO CheerioCrawler: https://warehouse-theme-metal.myshopify.com/products/sony-xbr55a8f-55-inch-4k-ultra-hd-smart-bravia-oled-tv
INFO CheerioCrawler: https://warehouse-theme-metal.myshopify.com/products/klipsch-r-120sw-powerful-detailed-home-speaker-set-of-1
...
In the final stats, we can see that we made 25 requests (1 listing page + 24 product pages) in just a few seconds. What we cannot see is that these requests are not made all at once without planning, but are scheduled and sent in a way that doesn't overload the target server. And if they do, Crawlee can automatically retry them.
Extracting data
The CheerioCrawler provides the handler with the $ attribute, which contains the parsed HTML of the handled page. This is the same $ object we used in our previous program. Let's locate and extract the same data as before:
crawler.router.addDefaultHandler(async ({ enqueueLinks }) => {
await enqueueLinks({ selector: '.product-list a.product-item__title', label: 'DETAIL' });
});
crawler.router.addHandler('DETAIL', async ({ $, request, log }) => {
const item = {
url: request.url,
title: $('.product-meta__title').text().trim(),
vendor: $('.product-meta__vendor').text().trim(),
};
log.info('Item scraped', item);
});
Now for the price. We're not doing anything new here - just copy-paste the code from our old scraper. The only change will be in the selector.
In oldindex.js, we look for .price within a $productItem object representing a product card. Here, we're looking for .price within the entire product detail page. It's better to be more specific so we don't accidentally match another price on the same page:
crawler.router.addHandler('DETAIL', async ({ $, request, log }) => {
const $price = $(".product-form__info-content .price").contents().last();
const priceRange = { minPrice: null, price: null };
const priceText = $price
.text()
.trim()
.replace("$", "")
.replace(".", "")
.replace(",", "");
if (priceText.startsWith("From ")) {
priceRange.minPrice = parseInt(priceText.replace("From ", ""));
} else {
priceRange.minPrice = parseInt(priceText);
priceRange.price = priceRange.minPrice;
}
const item = {
url: request.url,
title: $(".product-meta__title").text().trim(),
vendor: $('.product-meta__vendor').text().trim(),
...priceRange,
};
log.info('Item scraped', item);
});
Finally, the variants. We can reuse the parseVariant() function as-is. In the handler, we'll take some inspiration from what we have in oldindex.js, but since we're just logging the items and don't need to return them, the loop can be simpler. First, in the item data, we'll set variantName to null as a default value. If there are no variants, we'll log the item data as-is. If there are variants, we'll parse each one, merge the variant data with the item data, and log each resulting object. The full program will look like this:
import { CheerioCrawler } from 'crawlee';
function parseVariant($option) {
const [variantName, priceText] = $option
.text()
.trim()
.split(" - ");
const price = parseInt(
priceText
.replace("$", "")
.replace(".", "")
.replace(",", "")
);
return { variantName, price };
}
const crawler = new CheerioCrawler();
crawler.router.addDefaultHandler(async ({ enqueueLinks }) => {
await enqueueLinks({ selector: '.product-list a.product-item__title', label: 'DETAIL' });
});
crawler.router.addHandler('DETAIL', async ({ $, request, log }) => {
const $price = $(".product-form__info-content .price").contents().last();
const priceRange = { minPrice: null, price: null };
const priceText = $price
.text()
.trim()
.replace("$", "")
.replace(".", "")
.replace(",", "");
if (priceText.startsWith("From ")) {
priceRange.minPrice = parseInt(priceText.replace("From ", ""));
} else {
priceRange.minPrice = parseInt(priceText);
priceRange.price = priceRange.minPrice;
}
const item = {
url: request.url,
title: $(".product-meta__title").text().trim(),
vendor: $('.product-meta__vendor').text().trim(),
...priceRange,
variantName: null,
};
const $variants = $(".product-form__option.no-js option");
if ($variants.length === 0) {
log.info('Item scraped', item);
} else {
for (const element of $variants.toArray()) {
const variant = parseVariant($(element));
log.info('Item scraped', { ...item, ...variant });
}
}
});
await crawler.run(['https://warehouse-theme-metal.myshopify.com/collections/sales']);
If we run this scraper, we should get the same data for the 24 products as before. Crawlee has saved us a lot of effort by managing downloading, parsing, and parallelization.
Crawlee doesn't do much to help with locating and extracting the data - that part of the code remains almost the same, framework or not. This is because the detective work of finding and extracting the right data is the core value of custom scrapers. With Crawlee, we can focus on just that while letting the framework take care of everything else.
Saving data
Now that we're letting the framework take care of everything else, let's see what it can do about saving data. As of now, the product detail page handler logs each item as soon as it's ready. Instead, we can push the item to Crawlee's default dataset:
const crawler = new CheerioCrawler();
crawler.router.addHandler('DETAIL', async ({ $, request, pushData }) => {
...
const $variants = $(".product-form__option.no-js option");
if ($variants.length === 0) {
await pushData(item);
} else {
for (const element of $variants.toArray()) {
const variant = parseVariant($(element));
await pushData({ ...item, ...variant });
}
}
});
That's it! If we run the program now, there should be a storage directory alongside the index.js file. Crawlee uses it to store its internal state. If we go to the storage/datasets/default subdirectory, we'll see over 30 JSON files, each representing a single item.
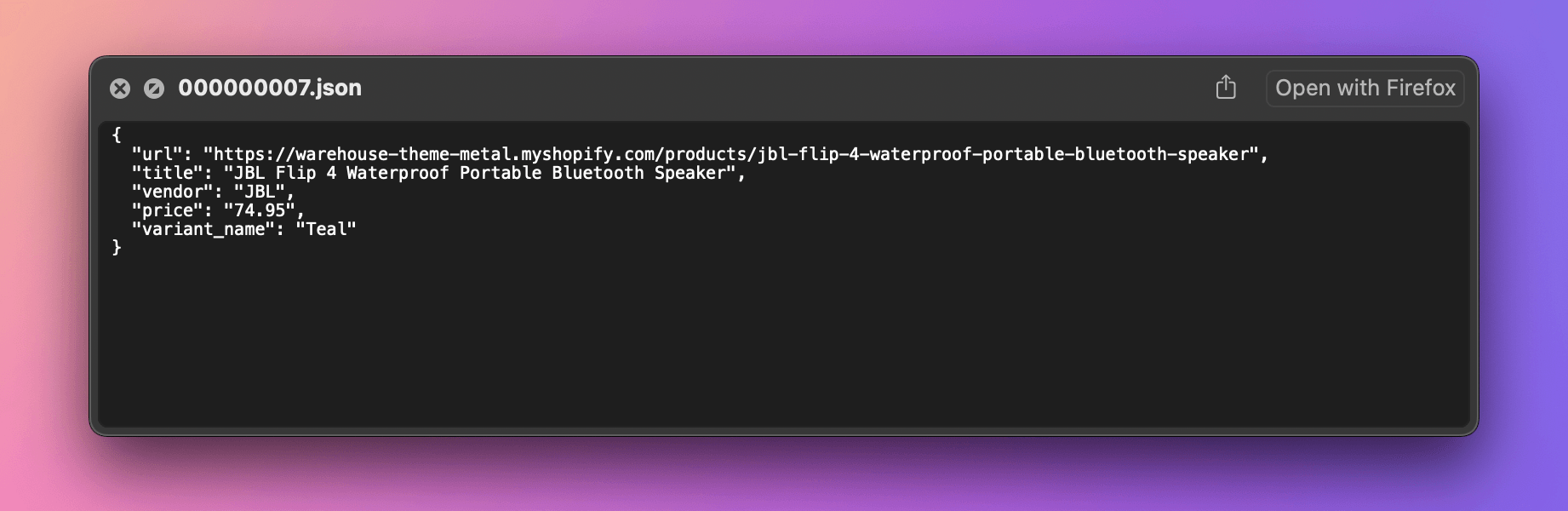
We can also export all the items to a single file of our choice. We'll do it at the end of the program, after the crawler has finished scraping:
await crawler.run(['https://warehouse-theme-metal.myshopify.com/collections/sales']);
await crawler.exportData('dataset.json');
await crawler.exportData('dataset.csv');
After running the scraper again, there should be two new files in your directory, dataset.json and dataset.csv, containing all the data.
Logging
Crawlee gives us stats about HTTP requests and concurrency, but once we started using pushData() instead of log.info(), we lost visibility into the pages we're crawling and the items we're saving. Let's add back some custom logging:
import { CheerioCrawler } from 'crawlee';
function parseVariant($option) {
const [variantName, priceText] = $option
.text()
.trim()
.split(" - ");
const price = parseInt(
priceText
.replace("$", "")
.replace(".", "")
.replace(",", "")
);
return { variantName, price };
}
const crawler = new CheerioCrawler();
crawler.router.addDefaultHandler(async ({ enqueueLinks, log }) => {
log.info('Looking for product detail pages');
await enqueueLinks({ selector: '.product-list a.product-item__title', label: 'DETAIL' });
});
crawler.router.addHandler('DETAIL', async ({ $, request, pushData, log }) => {
log.info(`Product detail page: ${request.url}`);
const $price = $(".product-form__info-content .price").contents().last();
const priceRange = { minPrice: null, price: null };
const priceText = $price
.text()
.trim()
.replace("$", "")
.replace(".", "")
.replace(",", "");
if (priceText.startsWith("From ")) {
priceRange.minPrice = parseInt(priceText.replace("From ", ""));
} else {
priceRange.minPrice = parseInt(priceText);
priceRange.price = priceRange.minPrice;
}
const item = {
url: request.url,
title: $(".product-meta__title").text().trim(),
vendor: $('.product-meta__vendor').text().trim(),
...priceRange,
variantName: null,
};
const $variants = $(".product-form__option.no-js option");
if ($variants.length === 0) {
log.info('Saving a product');
await pushData(item);
} else {
for (const element of $variants.toArray()) {
const variant = parseVariant($(element));
log.info('Saving a product variant');
await pushData({ ...item, ...variant });
}
}
});
await crawler.run(['https://warehouse-theme-metal.myshopify.com/collections/sales']);
crawler.log.info('Exporting data');
await crawler.exportData('dataset.json');
await crawler.exportData('dataset.csv');
Depending on what we find helpful, we can tweak the logs to include more or less detail. Check the Crawlee docs on the Log instance for more details on what you can do with it.
If we compare index.js and oldindex.js now, it's clear we've cut at least 20 lines of code compared to the original program, even with the extra logging we've added. Throughout this lesson, we've introduced features to match the old scraper's functionality, but at each phase, the code remained clean and readable. Plus, we've been able to focus on what's unique to the website we're scraping and the data we care about.
In the next lesson, we'll use a scraping platform to set up our application to run automatically every day.
Exercises
These challenges are here to help you test what you’ve learned in this lesson. Try to resist the urge to peek at the solutions right away. Remember, the best learning happens when you dive in and do it yourself!
You're about to touch the real web, which is practical and exciting! But websites change, so some exercises might break. If you run into any issues, please leave a comment below or file a GitHub Issue.
Build a Crawlee scraper of F1 Academy drivers
Scrape information about all F1 Academy drivers listed on the official Drivers page. Each item you push to Crawlee's default dataset should include the following data:
- URL of the driver's f1academy.com page
- Name
- Team
- Nationality
- Date of birth (as a string in
YYYY-MM-DDformat) - Instagram URL
If you export the dataset as JSON, it should look something like this:
[
{
"url": "https://www.f1academy.com/Racing-Series/Drivers/29/Emely-De-Heus",
"name": "Emely De Heus",
"team": "MP Motorsport",
"nationality": "Dutch",
"dob": "2003-02-10",
"instagram_url": "https://www.instagram.com/emely.de.heus/",
},
{
"url": "https://www.f1academy.com/Racing-Series/Drivers/28/Hamda-Al-Qubaisi",
"name": "Hamda Al Qubaisi",
"team": "MP Motorsport",
"nationality": "Emirati",
"dob": "2002-08-08",
"instagram_url": "https://www.instagram.com/hamdaalqubaisi_official/",
},
...
]
- The website uses
DD/MM/YYYYformat for the date of birth. You'll need to change the format to the ISO 8601 standard with dashes:YYYY-MM-DD - To locate the Instagram URL, use the attribute selector
a[href*='instagram']. Learn more about attribute selectors in the MDN docs.
Solution
import { CheerioCrawler } from 'crawlee';
const crawler = new CheerioCrawler();
crawler.router.addDefaultHandler(async ({ enqueueLinks }) => {
await enqueueLinks({ selector: '.teams-driver-item a', label: 'DRIVER' });
});
crawler.router.addHandler('DRIVER', async ({ $, request, pushData }) => {
const info = {};
for (const itemElement of $('.common-driver-info li').toArray()) {
const name = $(itemElement).find('span').text().trim();
const value = $(itemElement).find('h4').text().trim();
info[name] = value;
}
const detail = {};
for (const linkElement of $('.driver-detail--cta-group a').toArray()) {
const name = $(linkElement).find('p').text().trim();
const value = $(linkElement).find('h2').text().trim();
detail[name] = value;
}
const dob = info.DOB ?? '';
const [dobDay = '', dobMonth = '', dobYear = ''] = dob.split('/');
await pushData({
url: request.url,
name: $('h1').text().trim(),
team: detail.Team,
nationality: info.Nationality,
dob: dobYear && dobMonth && dobDay ? `${dobYear}-${dobMonth}-${dobDay}` : null,
instagram_url: $(".common-social-share a[href*='instagram']").attr('href') ?? null,
});
});
await crawler.run(['https://www.f1academy.com/Racing-Series/Drivers']);
await crawler.exportData('dataset.json');
Use Crawlee to find the user scores of popular Netflix titles
The Global Top 10 page has tables listing popular Netflix titles worldwide. Scrape the first 5 title names from this page, search for each title on TMDb. Assume the first search result is correct and retrieve the title's user score. Each item you push to Crawlee's default dataset should include the following data:
- URL of the title's TMDb page
- Title
- User score
If you export the dataset as JSON, it should look something like this:
[
{
"url": "https://www.themoviedb.org/movie/1290417-thrash",
"title": "Thrash",
"user_score": "59%"
},
{
"url": "https://www.themoviedb.org/movie/1629369-the-truth-and-tragedy-of-moriah-wilson",
"title": "The Truth and Tragedy of Moriah Wilson",
"user_score": "71%"
},
{
"url": "https://www.themoviedb.org/movie/1234731-anaconda",
"title": "Anaconda",
"user_score": "59%"
},
...
]
To scrape TMDb data, you need to construct a Request object with the appropriate search URL for each title name. The following code snippet gives you an idea of how to do this:
import { CheerioCrawler, Request } from 'crawlee';
import { escape } from 'node:querystring';
const tmdbSearchUrl = `https://www.themoviedb.org/search?query=${escape(name)}`;
const request = new Request({ url: tmdbSearchUrl, label: 'TMDB_SEARCH' });
Then use the addRequests() function to instruct Crawlee that it should follow an array of these manually constructed requests:
crawler.router.addDefaultHandler(async ({ $, addRequests }) => {
...
await addRequests(requests);
});
When navigating to the first TMDb search result, you might find it helpful to know that enqueueLinks() accepts a limit option, letting you specify the max number of HTTP requests to enqueue.
Solution
import { escape } from 'node:querystring';
import { CheerioCrawler, Request } from 'crawlee';
const crawler = new CheerioCrawler();
crawler.router.addDefaultHandler(async ({ $, addRequests }) => {
const buttons = $("[data-uia='top10-table-row-title'] button").toArray().slice(0, 5);
const requests = buttons.map((buttonElement) => {
const name = $(buttonElement).text().trim();
const tmdbSearchUrl = `https://www.themoviedb.org/search?query=${escape(name)}`;
return new Request({ url: tmdbSearchUrl, label: 'TMDB_SEARCH' });
});
await addRequests(requests);
});
crawler.router.addHandler('TMDB_SEARCH', async ({ enqueueLinks }) => {
await enqueueLinks({ selector: '.results a', label: 'TMDB', limit: 1 });
});
crawler.router.addHandler('TMDB', async ({ $, request, pushData }) => {
const title = $('.title a').first().text().trim();
const userScore = $('.user_score_chart').first().attr('data-percent');
if (title && userScore) {
await pushData({
url: request.url,
title,
user_score: `${userScore}%`,
});
}
});
await crawler.run(['https://www.netflix.com/tudum/top10']);
await crawler.exportData('dataset.json');