Saving data with Python
In this lesson, we'll save the data we scraped in the popular formats, such as CSV or JSON. We'll use Python's standard library to export the files.
We managed to scrape data about products and print it, with each product separated by a new line and each field separated by the | character. This already produces structured text that can be parsed, i.e., read programmatically.
$ python main.py
JBL Flip 4 Waterproof Portable Bluetooth Speaker | 74.95 | 74.95
Sony XBR-950G BRAVIA 4K HDR Ultra HD TV | 1398.00 | None
...
However, the format of this text is rather ad hoc and does not adhere to any specific standard that others could follow. It's unclear what to do if a product title already contains the | character or how to represent multi-line product descriptions. No ready-made library can handle all the parsing.
We should use widely popular formats that have well-defined solutions for all the corner cases and that other programs can read without much effort. Two such formats are CSV (Comma-separated values) and JSON (JavaScript Object Notation).
Collecting data
Producing results line by line is an efficient approach to handling large datasets, but to simplify this lesson, we'll store all our data in one variable. This'll take three changes to our program:
import httpx
from bs4 import BeautifulSoup
url = "https://warehouse-theme-metal.myshopify.com/collections/sales"
response = httpx.get(url)
response.raise_for_status()
html_code = response.text
soup = BeautifulSoup(html_code, "html.parser")
data = []
for product in soup.select(".product-item"):
title = product.select_one(".product-item__title").text.strip()
price_text = (
product
.select_one(".price")
.contents[-1]
.strip()
.replace("$", "")
.replace(".", "")
.replace(",", "")
)
if price_text.startswith("From "):
min_price = int(price_text.removeprefix("From "))
price = None
else:
min_price = int(price_text)
price = min_price
data.append({"title": title, "min_price": min_price, "price": price})
print(data)
Before looping over the products, we prepare an empty list. Then, instead of printing each line, we append the data of each product to the list in the form of a Python dictionary. At the end of the program, we print the entire list. The program should now print the results as a single large Python list:
$ python main.py
[{'title': 'JBL Flip 4 Waterproof Portable Bluetooth Speaker', 'min_price': 7495, 'price': 7495}, {'title': 'Sony XBR-950G BRAVIA 4K HDR Ultra HD TV', 'min_price': 139800, 'price': None}, ...]
If you find the complex data structures printed by print() difficult to read, try using pp() from the pprint module instead.
Saving data as JSON
The JSON format is popular primarily among developers. We use it for storing data, configuration files, or as a way to transfer data between programs (e.g., APIs). Its origin stems from the syntax of objects in the JavaScript programming language, which is similar to the syntax of Python dictionaries.
In Python, we can read and write JSON using the json standard library module. We'll begin with imports:
import httpx
from bs4 import BeautifulSoup
import json
Next, instead of printing the data, we'll finish the program by exporting it to JSON. Let's replace the line print(data) with the following:
with open("products.json", "w") as file:
json.dump(data, file)
That's it! If we run our scraper now, it won't display any output, but it will create a products.json file in the current working directory, which contains all the data about the listed products:
[{"title": "JBL Flip 4 Waterproof Portable Bluetooth Speaker", "min_price": "7495", "price": "7495"}, {"title": "Sony XBR-950G BRAVIA 4K HDR Ultra HD TV", "min_price": "139800", "price": null}, ...]
If you skim through the data, you'll notice that the json.dump() function handled some potential issues, such as escaping double quotes found in one of the titles by adding a backslash:
{"title": "Sony SACS9 10\" Active Subwoofer", "min_price": "15800", "price": "15800"}
While a compact JSON file without any whitespace is efficient for computers, it can be difficult for humans to read. You can pass indent=2 to json.dump() for prettier output.
Also, if your data contains non-English characters, set ensure_ascii=False. By default, Python encodes everything except ASCII, which means it would save Bún bò Nam Bô as B\\u00fan b\\u00f2 Nam B\\u00f4.
Saving data as CSV
The CSV format is popular among data analysts because a wide range of tools can import it, including spreadsheets apps like LibreOffice Calc, Microsoft Excel, Apple Numbers, and Google Sheets.
In Python, we can read and write CSV using the csv standard library module. First let's try something small in the Python's interactive REPL to familiarize ourselves with the basic usage:
>>> import csv
>>> with open("data.csv", "w") as file:
... writer = csv.DictWriter(file, fieldnames=["name", "age", "hobbies"])
... writer.writeheader()
... writer.writerow({"name": "Alice", "age": 24, "hobbies": "kickbox, Python"})
... writer.writerow({"name": "Bob", "age": 42, "hobbies": "reading, TypeScript"})
...
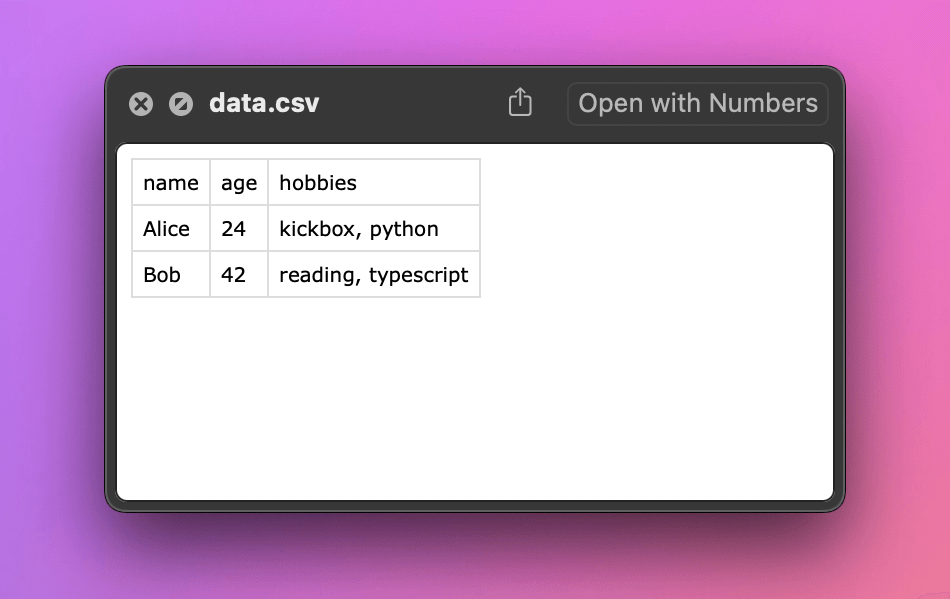
We first opened a new file for writing and created a DictWriter() instance with the expected field names. We instructed it to write the header row first and then added two more rows containing actual data. The code produced a data.csv file in the same directory where we're running the REPL. It has the following contents:
name,age,hobbies
Alice,24,"kickbox, Python"
Bob,42,"reading, TypeScript"
In the CSV format, if a value contains commas, we should enclose it in quotes. When we open the file in a text editor of our choice, we can see that the writer automatically handled this.
When browsing the directory on macOS, we can see a nice preview of the file's contents, which proves that the file is correct and that other programs can read it. If you're using a different operating system, try opening the file with any spreadsheet program you have.
Now that's nice, but we didn't want Alice, Bob, kickbox, or TypeScript. What we actually want is a CSV containing Sony XBR-950G BRAVIA 4K HDR Ultra HD TV, right? Let's do this! First, let's add csv to our imports:
import httpx
from bs4 import BeautifulSoup
import json
import csv
Next, let's add one more data export to end of the source code of our scraper:
with open("products.json", "w") as file:
json.dump(data, file)
with open("products.csv", "w") as file:
writer = csv.DictWriter(file, fieldnames=["title", "min_price", "price"])
writer.writeheader()
for row in data:
writer.writerow(row)
The program should now also produce a CSV file with the following content:
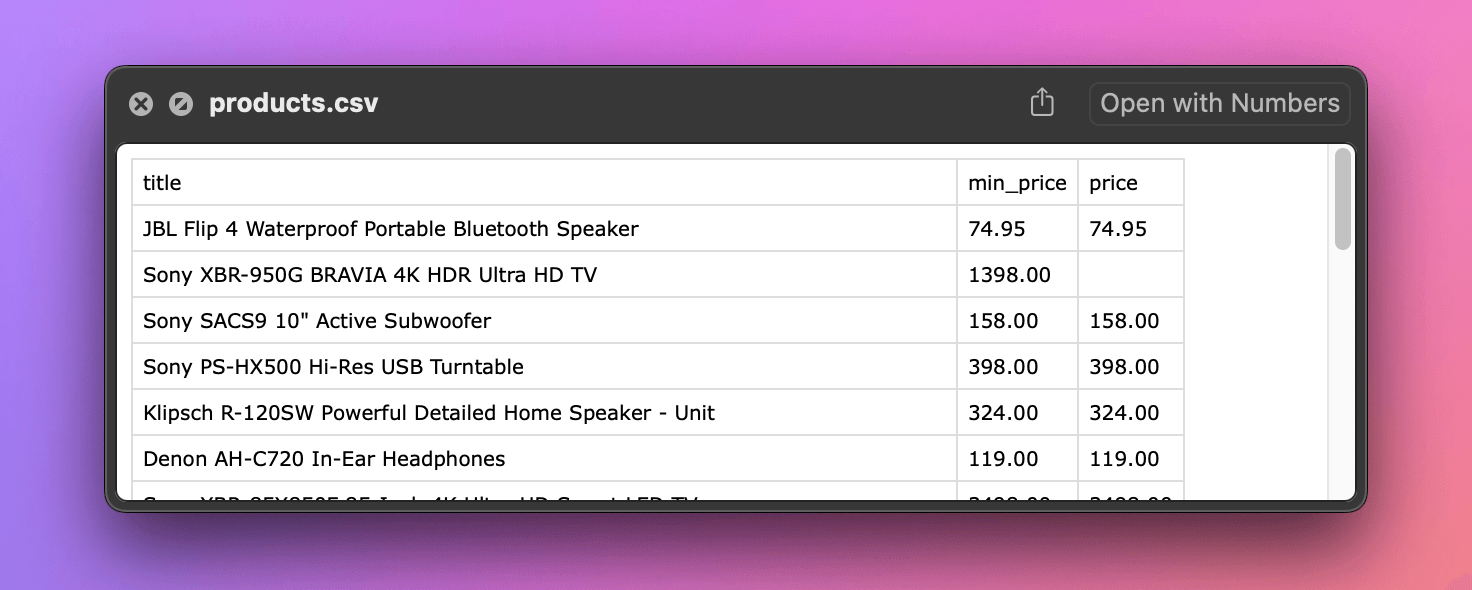
We've built a Python application that downloads a product listing, parses the data, and saves it in a structured format for further use. But the data still has gaps: for some products, we only have the min price, not the actual prices. In the next lesson, we'll attempt to scrape more details from all the product pages.
Exercises
In this lesson, we created export files in two formats. The following challenges are designed to help you empathize with the people who'd be working with them.
Process your JSON
Write a new Python program that reads the products.json file we created in this lesson, finds all products with a min price greater than $500, and prints each one using pp().
Solution
import json
from pprint import pp
with open('products.json', 'r', encoding='utf-8') as file:
products = json.load(file)
for product in products:
if int(product["min_price"]) > 50000:
pp(product)
Process your CSV
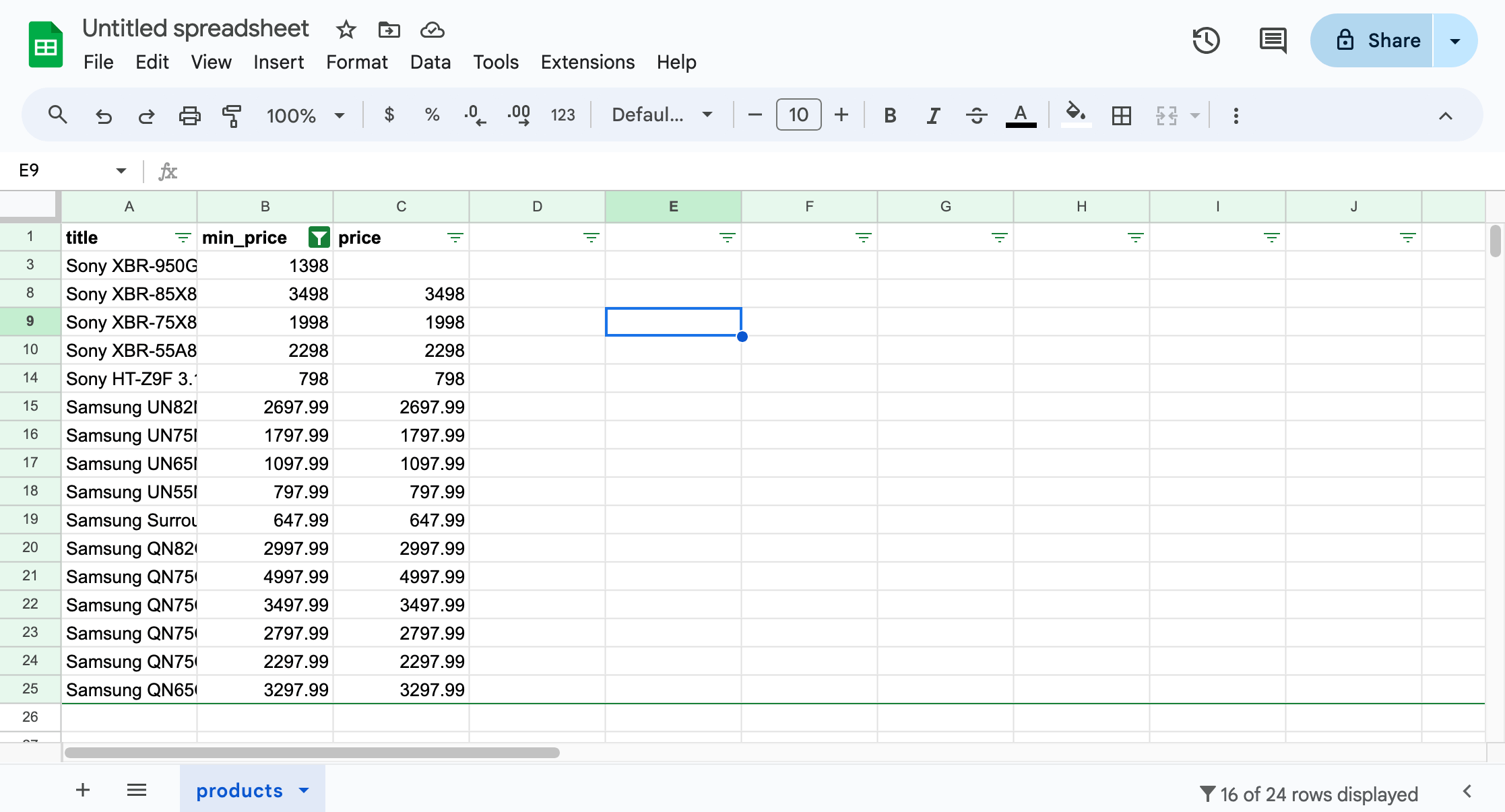
Open the products.csv file we created in the lesson using a spreadsheet application. Then, in the app, find all products with a min price greater than $500.
Solution
Let's use Google Sheets, which is free to use. After logging in with a Google account:
- Go to File > Import, choose Upload, and select the file. Import the data using the default settings. You should see a table with all the data.
- Select the header row. Go to Data > Create filter.
- Use the filter icon that appears next to
min_price. Choose Filter by condition, select Greater than, and enter 500 in the text field. Confirm the dialog. You should see only the filtered data.