Parsing HTML with Python
In this lesson we'll look for products in the downloaded HTML. We'll use BeautifulSoup to turn the HTML into objects which we can work with in our Python program.
From lessons about browser DevTools we know that the HTML elements representing individual products have a class attribute which, among other values, contains product-item.

As a first step, let's try counting how many products are on the listing page.
Processing HTML
After downloading, the entire HTML is available in our program as a string. We can print it to the screen or save it to a file, but not much more. However, since it's a string, could we use string operations or regular expressions to count the products?
While somewhat possible, such an approach is tedious, fragile, and unreliable. To work with HTML, we need a robust tool dedicated to the task: an HTML parser. It takes a text with HTML markup and turns it into a tree of Python objects.
While Bobince's infamous StackOverflow answer is funny, it doesn't go very deep into the reasoning:
- In formal language theory, HTML's hierarchical, nested structure makes it a context-free language. Regular expressions, by contrast, match patterns in regular languages, which are much simpler.
- Because of this difference, regex alone struggles with HTML's nested tags. On top of that, HTML has complex syntax rules and countless edge cases, which only add to the difficulty.
We'll choose Beautiful Soup as our parser, as it's a popular library renowned for its ability to process even non-standard, broken markup. This is useful for scraping, because real-world websites often contain all sorts of errors and discrepancies.
$ pip install beautifulsoup4
...
Successfully installed beautifulsoup4-4.0.0 soupsieve-0.0
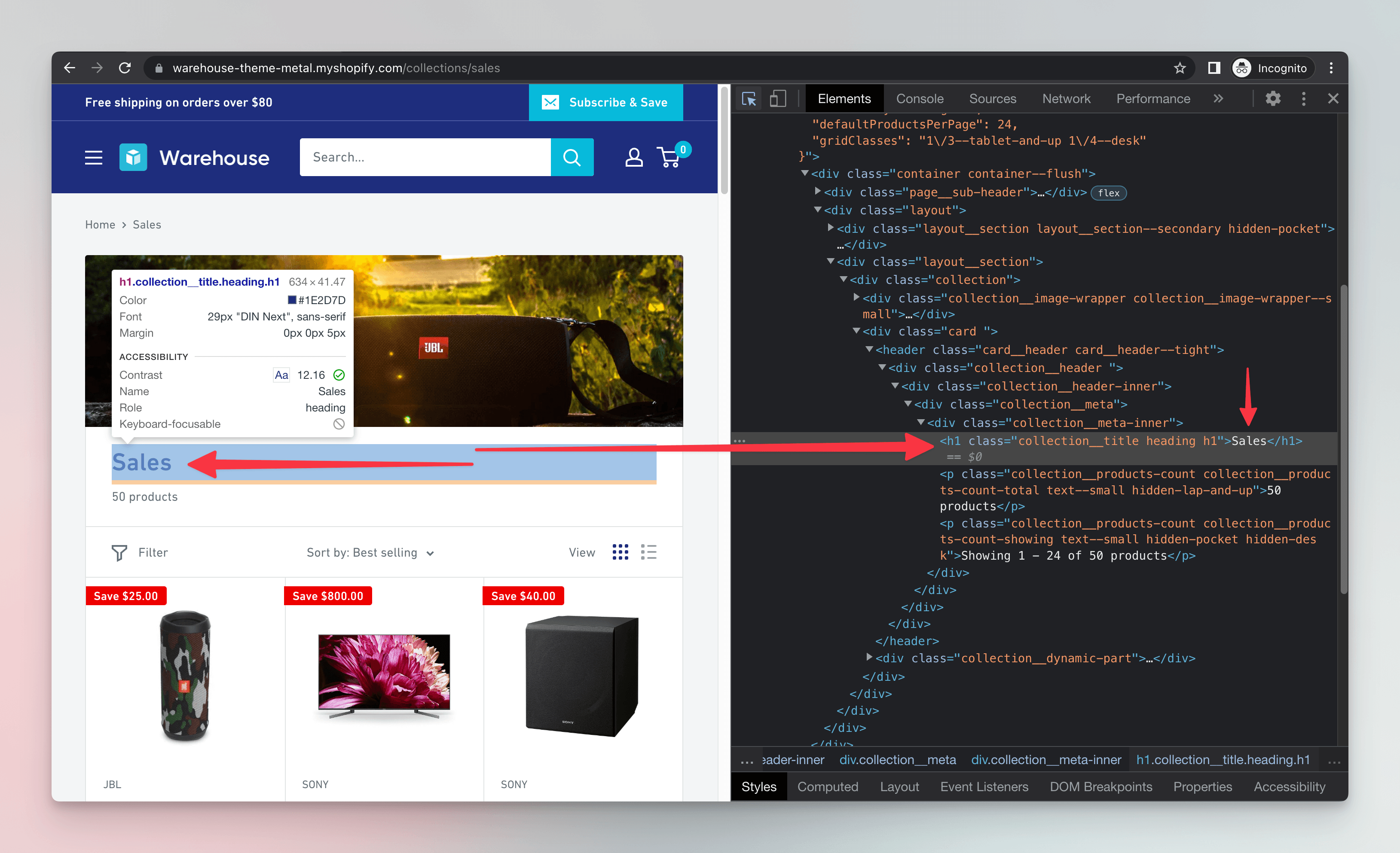
Now let's use it for parsing the HTML. The BeautifulSoup object allows us to work with the HTML elements in a structured way. As a demonstration, we'll first get the <h1> element, which represents the main heading of the page.
We'll update our code to the following:
import httpx
from bs4 import BeautifulSoup
url = "https://warehouse-theme-metal.myshopify.com/collections/sales"
response = httpx.get(url)
response.raise_for_status()
html_code = response.text
soup = BeautifulSoup(html_code, "html.parser")
print(soup.select("h1"))
Then let's run the program:
$ python main.py
[<h1 class="collection__title heading h1">Sales</h1>]
Our code lists all h1 elements it can find in the HTML we gave it. It's the case that there's just one, so in the result we can see a list with a single item. What if we want to print just the text? Let's change the end of the program to the following:
headings = soup.select("h1")
first_heading = headings[0]
print(first_heading.text)
If we run our scraper again, it prints the text of the first h1 element:
$ python main.py
Sales
The Warehouse returns full HTML in its initial response, but many other sites add some content after the page loads or after user interaction. In such cases, what we'd see in DevTools could differ from response.text in Python. Learn how to handle these scenarios in our API Scraping and Puppeteer & Playwright courses.
Using CSS selectors
Beautiful Soup's .select() method runs a CSS selector against a parsed HTML document and returns all the matching elements. It's like calling document.querySelectorAll() in browser DevTools.
Scanning through usage examples will help us to figure out code for counting the product cards:
import httpx
from bs4 import BeautifulSoup
url = "https://warehouse-theme-metal.myshopify.com/collections/sales"
response = httpx.get(url)
response.raise_for_status()
html_code = response.text
soup = BeautifulSoup(html_code, "html.parser")
products = soup.select(".product-item")
print(len(products))
In CSS, .product-item selects all elements whose class attribute contains value product-item. We call soup.select() with the selector and get back a list of matching elements. Beautiful Soup handles all the complexity of understanding the HTML markup for us. On the last line, we use len() to count how many items there is in the list.
$ python main.py
24
That's it! We've managed to download a product listing, parse its HTML, and count how many products it contains. In the next lesson, we'll be looking for a way to extract detailed information about individual products.
Exercises
These challenges are here to help you test what you’ve learned in this lesson. Try to resist the urge to peek at the solutions right away. Remember, the best learning happens when you dive in and do it yourself!
You're about to touch the real web, which is practical and exciting! But websites change, so some exercises might break. If you run into any issues, please leave a comment below or file a GitHub Issue.
Scrape F1 Academy teams
Print a total count of F1 Academy teams listed on this page:
https://www.f1academy.com/Racing-Series/Teams
Solution
import httpx
from bs4 import BeautifulSoup
url = "https://www.f1academy.com/Racing-Series/Teams"
response = httpx.get(url)
response.raise_for_status()
soup = BeautifulSoup(response.text, "html.parser")
print(len(soup.select('.teams-driver-item')))
Scrape F1 Academy drivers
Use the same URL as in the previous exercise, but this time print a total count of F1 Academy drivers.
Solution
import httpx
from bs4 import BeautifulSoup
url = "https://www.f1academy.com/Racing-Series/Teams"
response = httpx.get(url)
response.raise_for_status()
soup = BeautifulSoup(response.text, "html.parser")
print(len(soup.select('.driver')))