Crawling websites with Python
In this lesson, we'll follow links to individual product pages. We'll use HTTPX to download them and BeautifulSoup to process them.
In previous lessons we've managed to download the HTML code of a single page, parse it with BeautifulSoup, and extract relevant data from it. We'll do the same now for each of the products.
Thanks to the refactoring, we have functions ready for each of the tasks, so we won't need to repeat ourselves in our code. This is what you should see in your editor now:
import httpx
from bs4 import BeautifulSoup
import json
import csv
from urllib.parse import urljoin
def download(url):
response = httpx.get(url)
response.raise_for_status()
html_code = response.text
return BeautifulSoup(html_code, "html.parser")
def parse_product(product, base_url):
title_element = product.select_one(".product-item__title")
title = title_element.text.strip()
url = urljoin(base_url, title_element["href"])
price_text = (
product
.select_one(".price")
.contents[-1]
.strip()
.replace("$", "")
.replace(".", "")
.replace(",", "")
)
if price_text.startswith("From "):
min_price = int(price_text.removeprefix("From "))
price = None
else:
min_price = int(price_text)
price = min_price
return {"title": title, "min_price": min_price, "price": price, "url": url}
def export_json(file, data):
json.dump(data, file, indent=2)
def export_csv(file, data):
fieldnames = list(data[0].keys())
writer = csv.DictWriter(file, fieldnames=fieldnames)
writer.writeheader()
for row in data:
writer.writerow(row)
listing_url = "https://warehouse-theme-metal.myshopify.com/collections/sales"
listing_soup = download(listing_url)
data = []
for product in listing_soup.select(".product-item"):
item = parse_product(product, listing_url)
data.append(item)
with open("products.json", "w") as file:
export_json(file, data)
with open("products.csv", "w") as file:
export_csv(file, data)
Extracting vendor name
Each product URL points to a so-called product detail page, or PDP. If we open one of the product URLs in the browser, e.g. the one about Sony XBR-950G BRAVIA, we can see that it contains a vendor name, SKU, number of reviews, product images, product variants, stock availability, description, and perhaps more.
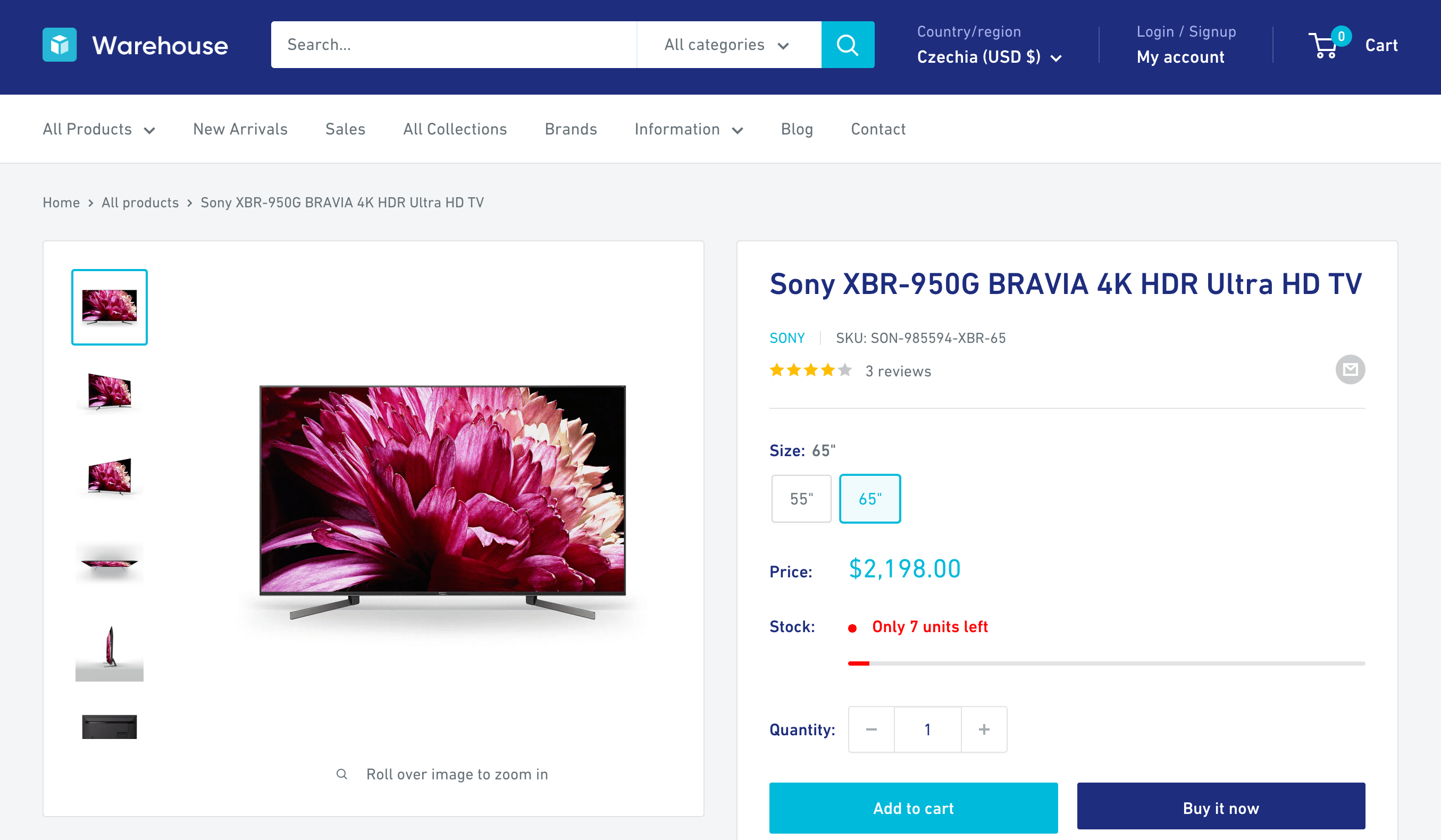
Depending on what's valuable for our use case, we can now use the same techniques as in previous lessons to extract any of the above. As a demonstration, let's scrape the vendor name. In browser DevTools, we can see that the HTML around the vendor name has the following structure:
<div class="product-meta">
<h1 class="product-meta__title heading h1">
Sony XBR-950G BRAVIA 4K HDR Ultra HD TV
</h1>
<div class="product-meta__label-list">
...
</div>
<div class="product-meta__reference">
<a class="product-meta__vendor link link--accented" href="/collections/sony">
Sony
</a>
<span class="product-meta__sku">
SKU:
<span class="product-meta__sku-number">SON-985594-XBR-65</span>
</span>
</div>
<a href="#product-reviews" class="product-meta__reviews-badge link" data-offset="30">
<div class="rating">
<div class="rating__stars" role="img" aria-label="4.0 out of 5.0 stars">
...
</div>
<span class="rating__caption">3 reviews</span>
</div>
</a>
...
</div>
It looks like using a CSS selector to locate the element with the product-meta__vendor class, and then extracting its text, should be enough to get the vendor name as a string:
vendor = soup.select_one(".product-meta__vendor").text.strip()
But where do we put this line in our program?
Crawling product detail pages
In the data loop we're already going through all the products. Let's expand it to include downloading the product detail page, parsing it, extracting the vendor's name, and adding it as a new key in the item's dictionary:
listing_url = "https://warehouse-theme-metal.myshopify.com/collections/sales"
listing_soup = download(listing_url)
data = []
for product in listing_soup.select(".product-item"):
item = parse_product(product, listing_url)
product_soup = download(item["url"])
item["vendor"] = product_soup.select_one(".product-meta__vendor").text.strip()
data.append(item)
If we run the program now, it'll take longer to finish since it's making 24 more HTTP requests. But in the end, it should produce exports with a new field containing the vendor's name:
[
{
"title": "JBL Flip 4 Waterproof Portable Bluetooth Speaker",
"min_price": "7495",
"price": "7495",
"url": "https://warehouse-theme-metal.myshopify.com/products/jbl-flip-4-waterproof-portable-bluetooth-speaker",
"vendor": "JBL"
},
{
"title": "Sony XBR-950G BRAVIA 4K HDR Ultra HD TV",
"min_price": "139800",
"price": null,
"url": "https://warehouse-theme-metal.myshopify.com/products/sony-xbr-65x950g-65-class-64-5-diag-bravia-4k-hdr-ultra-hd-tv",
"vendor": "Sony"
},
...
]
Extracting price
Scraping the vendor's name is nice, but the main reason we started checking the detail pages in the first place was to figure out how to get a price for each product. From the product listing, we could only scrape the min price, and remember - we're building a Python app to track prices!
Looking at the Sony XBR-950G BRAVIA, it's clear that the listing only shows min prices, because some products have variants, each with a different price. And different stock availability. And different SKUs…
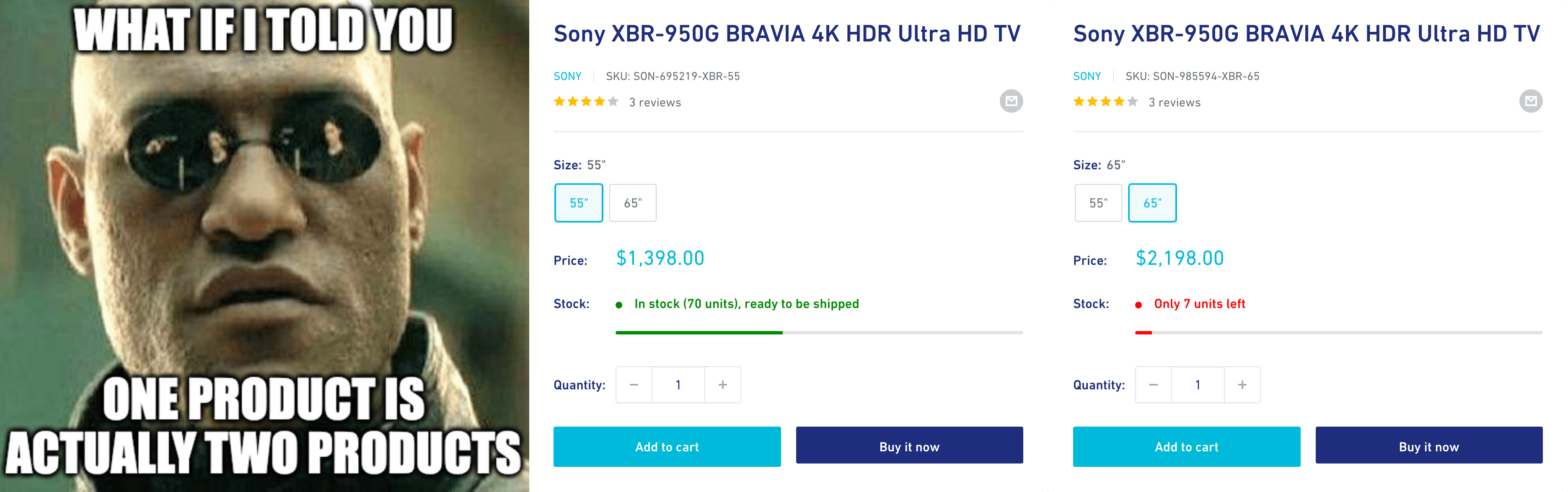
In the next lesson, we'll scrape the product detail pages so that each product variant is represented as a separate item in our dataset.
Exercises
These challenges are here to help you test what you’ve learned in this lesson. Try to resist the urge to peek at the solutions right away. Remember, the best learning happens when you dive in and do it yourself!
You're about to touch the real web, which is practical and exciting! But websites change, so some exercises might break. If you run into any issues, please leave a comment below or file a GitHub Issue.
Scrape birthplaces of top 5 tennis players
Scrape links to detail pages of the top 5 tennis players according to WTA rankings. Follow the links and extract the birthplace of each player. Print the URL of the player's detail page, then | as a separator, then the birthplace. Start with this URL:
https://www.wtatennis.com/rankings/singles
Your program should print the following:
https://www.wtatennis.com/players/320760/aryna-sabalenka | Minsk, Belarus
https://www.wtatennis.com/players/326408/iga-swiatek | Warsaw, Poland
https://www.wtatennis.com/players/328560/coco-gauff | Delray Beach, Fl. USA
https://www.wtatennis.com/players/326384/amanda-anisimova | Miami Beach, FL, USA
https://www.wtatennis.com/players/324166/elena-rybakina | Moscow, Russia
Solution
import httpx
from bs4 import BeautifulSoup
from urllib.parse import urljoin
def download(url: str) -> BeautifulSoup:
response = httpx.get(url)
response.raise_for_status()
return BeautifulSoup(response.text, "html.parser")
listing_url = "https://www.wtatennis.com/rankings/singles"
listing_soup = download(listing_url)
player_links = listing_soup.select(".rankings__list .player-row-drawer__link")
for link in player_links[:5]:
player_url = urljoin(listing_url, link["href"])
player_soup = download(player_url)
for info_block in player_soup.select(".profile-bio__info-block"):
label_text = info_block.select_one("h2").text.strip()
if label_text.lower() == "birthplace":
birthplace = info_block.select_one("span").text.strip()
print(player_url, "|", birthplace)
Scrape authors of F1 news articles
Scrape links to the Guardian's latest F1 news articles. For each article, follow the link and extract both the author's name and the article's title. Print the author's name and the title for all the articles. Start with this URL:
https://www.theguardian.com/sport/formulaone
Your program should print something like this:
Daniel Harris: Sports quiz of the week: Johan Neeskens, Bond and airborne antics
Colin Horgan: The NHL is getting its own Drive to Survive. But could it backfire?
Reuters: US GP ticket sales ‘took off’ after Max Verstappen stopped winning in F1
Giles Richards: Liam Lawson gets F1 chance to replace Pérez alongside Verstappen at Red Bull
PA Media: Lewis Hamilton reveals lifelong battle with depression after school bullying
...
- You can use attribute selectors to select HTML elements based on their attribute values.
- Sometimes a person authors the article, but other times it's contributed by a news agency.
Solution
import httpx
from bs4 import BeautifulSoup
from urllib.parse import urljoin
def download(url: str) -> BeautifulSoup:
response = httpx.get(url)
response.raise_for_status()
return BeautifulSoup(response.text, "html.parser")
def parse_author(article_soup: BeautifulSoup) -> str | None:
link = article_soup.select_one('a[rel="author"]')
if link:
return link.text.strip()
address = article_soup.select_one('aside address')
if address:
return address.text.strip()
return None
listing_url = "https://www.theguardian.com/sport/formulaone"
listing_soup = download(listing_url)
for item in listing_soup.select('#maincontent ul li'):
link = item.select_one('a')
if not link or 'href' not in link.attrs:
continue
article_url = urljoin(listing_url, link['href'])
article_soup = download(article_url)
title = article_soup.select_one('h1').text.strip()
author = parse_author(article_soup)
print(f"{author}: {title}")