IV - Reading & intercepting requests
You can use DevTools, but did you know that you can do all the same stuff (plus more) programmatically? Read and intercept requests in Puppeteer/Playwright.
On any website that serves up images, makes XMLHttpRequests, or fetches content in some other way, you can see those requests (and their responses) in the Network tab of your browser's DevTools. Lots of data about the request can be found there, such as the headers, payload, and response body.
In Playwright and Puppeteer, it is also possible to read (and even intercept) requests being made on the page - programmatically. This is very useful for things like reading dynamic headers, saving API responses, blocking certain resources, and much more.
During this lesson, we'll be using Tiësto's following list on SoundCloud to demonstrate request/response reading and interception. Here's our basic setup for opening the page:
- Playwright
- Puppeteer
import { chromium } from 'playwright';
const browser = await chromium.launch({ headless: false });
const page = await browser.newPage();
// Our code will go here
await page.goto('https://soundcloud.com/tiesto/following');
await page.waitForTimeout(10000);
await browser.close();
import puppeteer from 'puppeteer';
const browser = await puppeteer.launch({ headless: false });
const page = await browser.newPage();
// Our code will go here
await page.goto('https://soundcloud.com/tiesto/following');
await page.waitForTimeout(10000);
await browser.close();
Reading requests
We can use the page.on() function to listen for the request event, passing in a callback function. The first parameter of the passed in callback function is an object representing the request.
Upon visiting Tiësto's following page, we can see in the Network tab that a request is made to fetch all of the users which he is following.
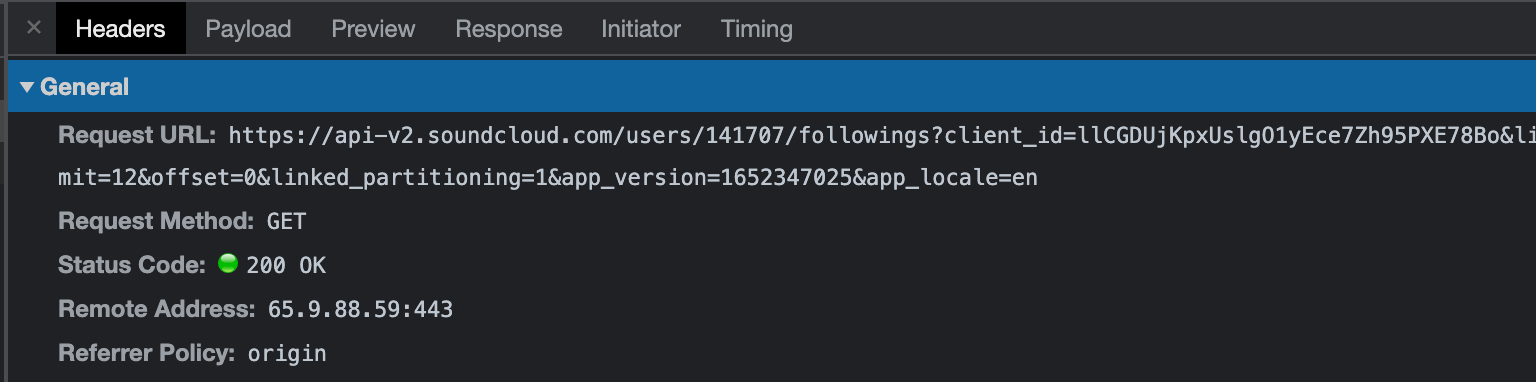
Let's go ahead and listen for this request in our code:
- Playwright
- Puppeteer
// Listen for all requests
page.on('request', (req) => {
// If the URL doesn't include our keyword, ignore it
if (!req.url().includes('followings')) return;
console.log('Request for followers was made!');
});
// Listen for all requests
page.on('request', (req) => {
// If the URL doesn't include our keyword, ignore it
if (!req.url().includes('followings')) return;
console.log('Request for followers was made!');
});
Note that you should always define any request reading/interception code prior to calling the
page.goto()function.
Cool! Now when we run our code, we'll see this logged to the console:
Request for followers was made!
This request includes some useful query parameters, namely the client_id. Let's go ahead and grab these values from the request URL and print them to the console:
- Playwright
- Puppeteer
import { chromium } from 'playwright';
const browser = await chromium.launch({ headless: false });
const page = await browser.newPage();
// Listen for all requests
page.on('request', (req) => {
// If the URL doesn't include our keyword, ignore it
if (!req.url().includes('followings')) return;
// Convert the request URL into a URL object
const url = new URL(req.url());
// Print the search parameters in object form
console.log(Object.fromEntries(url.searchParams));
});
await page.goto('https://soundcloud.com/tiesto/following');
await page.waitForTimeout(10000);
await browser.close();
import puppeteer from 'puppeteer';
const browser = await puppeteer.launch({ headless: false });
const page = await browser.newPage();
// Listen for all requests
page.on('request', (req) => {
// If the URL doesn't include our keyword, ignore it
if (!req.url().includes('followings')) return;
// Convert the request URL into a URL object
const url = new URL(req.url());
// Print the search parameters in object form
console.log(Object.fromEntries(url.searchParams));
});
await page.goto('https://soundcloud.com/tiesto/following');
await page.waitForTimeout(10000);
await browser.close();
After running this code, we can see this logged to the console:
{
client_id: 'llCGDUjKpxUslgO1yEce7Zh95PXE78Bo',
limit: '12',
offset: '0',
linked_partitioning: '1',
app_version: '1652347025',
app_locale: 'en'
}
Reading responses
Listening for and reading responses is very similar to reading requests. The only difference is that we need to listen for the response event instead of request. Additionally, the object passed into the callback function represents the response instead of the request.
This time, instead of grabbing the query parameters of the request URL, let's grab hold of the response body and print it to the console in JSON format:
- Playwright
- Puppeteer
// Notice that the callback function is now async
page.on('response', async (res) => {
if (!res.request().url().includes('followings')) return;
// Grab the response body in JSON format
try {
const json = await res.json();
console.log(json);
} catch (err) {
console.error('Response wasn\'t JSON or failed to parse response.');
}
});
// Notice that the callback function is now async
page.on('response', async (res) => {
if (!res.request().url().includes('followings')) return;
// Grab the response body in JSON format
try {
const json = await res.json();
console.log(json);
} catch (err) {
console.error('Response wasn\'t JSON or failed to parse response.');
}
});
Take notice of our usage of a
try...catchblock. This is because if the response is not JSON, theres.json()function will fail and throw an error, which we must handle to prevent any unexpected crashes.
Upon running this code, we'll see the API response logged into the console:
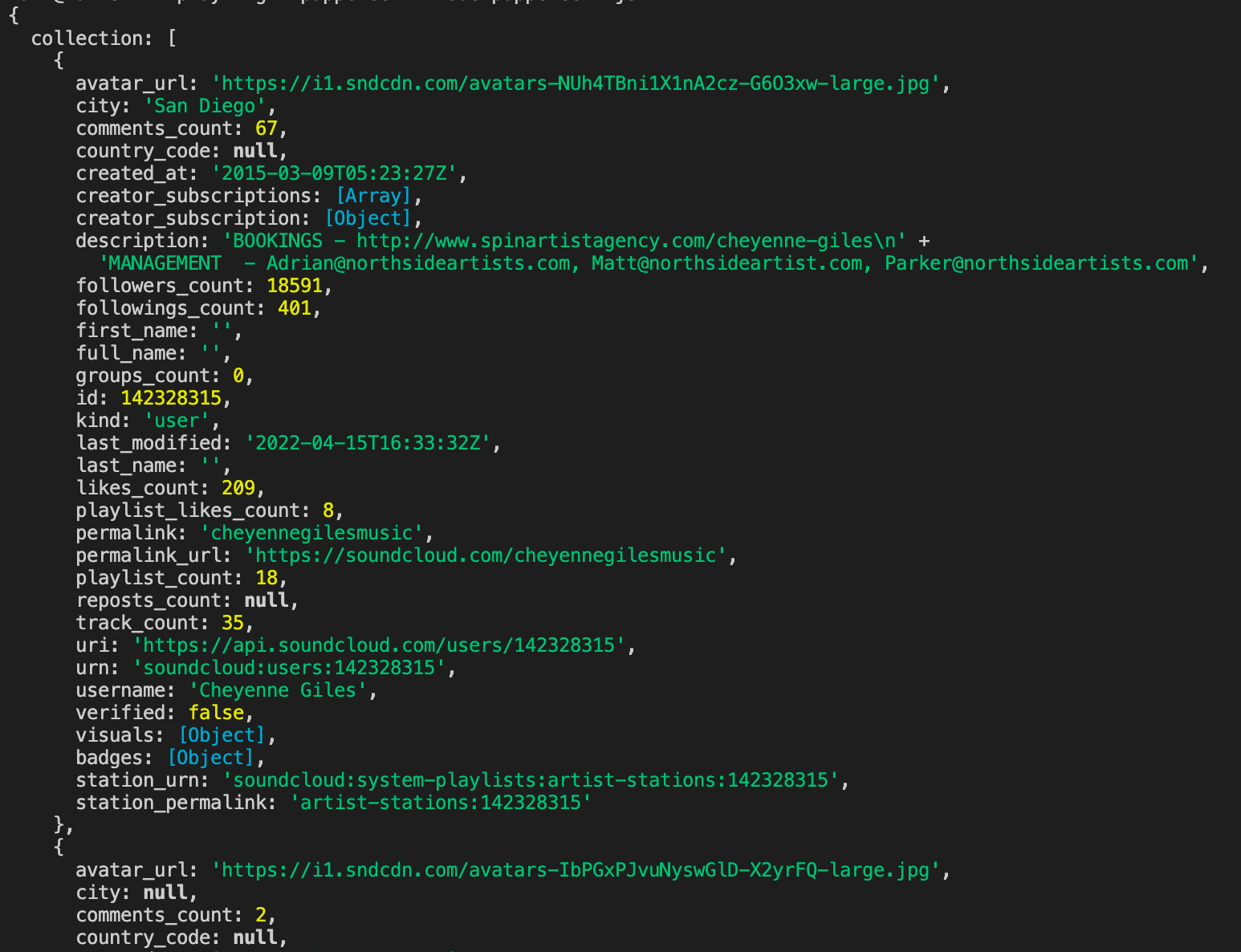
Intercepting requests
One of the most popular ways of speeding up website loading in Puppeteer and Playwright is by blocking certain resources from loading. These resources are usually CSS files, images, and other miscellaneous resources that aren't super necessary (mainly because the computer doesn't have eyes - it doesn't care how the website looks!).
In Puppeteer, we must first enable request interception with the page.setRequestInterception() function. Then, we can check whether or not the request's resource ends with one of our blocked file extensions. If so, we'll abort the request. Otherwise, we'll let it continue. All of this logic will still be within the page.on() method.
With Playwright, request interception is a bit different. We use the page.route() function instead of page.on(), passing in a string, regular expression, or a function that will match the URL of the request we'd like to read from. The second parameter is also a callback function, but with the Route object passed into it instead.
Blocking resources
We'll first create an array of some file extensions that we'd like to block:
const blockedExtensions = ['.png', '.css', '.jpg', '.jpeg', '.pdf', '.svg'];
Then, we'll abort() all requests that end with any of these extensions.
- Playwright
- Puppeteer
import { chromium } from 'playwright';
const browser = await chromium.launch({ headless: false });
const page = await browser.newPage();
const blockedExtensions = ['.png', '.css', '.jpg', '.jpeg', '.pdf', '.svg'];
// Only listen for requests with one of our blocked extensions
// Abort all matching requests
page.route(`**/*{${blockedExtensions.join(',')}}`, async (route) => route.abort());
await page.goto('https://soundcloud.com/tiesto/following');
await page.waitForTimeout(10000);
await browser.close();
import puppeteer from 'puppeteer';
const browser = await puppeteer.launch({ headless: false });
const page = await browser.newPage();
const blockedExtensions = ['.png', '.css', '.jpg', '.jpeg', '.pdf', '.svg'];
// Enable request interception (skipping this step will result in an error)
await page.setRequestInterception(true);
// Listen for all requests
page.on('request', async (req) => {
// If the request ends in a blocked extension, abort the request
if (blockedExtensions.some((str) => req.url().endsWith(str))) return req.abort();
// Otherwise, continue
await req.continue();
});
await page.goto('https://soundcloud.com/tiesto/following');
await page.waitForTimeout(10000);
await browser.close();
You can also use
request.resourceType()to grab the resource type.
Here's what we see when we run this logic:
This confirms that we've successfully blocked the CSS and image resources from loading.
Quick note about resource blocking
Something very important to note is that by using request interception, the browser's cache is turned off. This means that resources on websites that would normally be cached (and pulled from the cache instead on the next request for those resources) will not be cached, which can have varying negative effects on performance, especially when making many requests to the same domain, which is very common in web scraping. You can learn how to solve this problem in this short tutorial.
To block resources, it is better to use a CDP (Chrome DevTools Protocol) Session (Playwright/Puppeteer) to set the blocked URLs. Here is an implementation that achieves the same goal as our above example above; however, the browser's cache remains enabled.
- Playwright
- Puppeteer
// Note, you can't use CDP session in other browsers!
// Only in Chromium.
import { chromium } from 'playwright';
const browser = await chromium.launch({ headless: false });
const page = await browser.newPage();
// Define our blocked extensions
const blockedExtensions = ['.png', '.css', '.jpg', '.jpeg', '.pdf', '.svg'];
// Use CDP session to block resources
const client = await page.context().newCDPSession(page);
await client.send('Network.setBlockedURLs', { urls: blockedExtensions });
await page.goto('https://soundcloud.com/tiesto/following');
await page.waitForTimeout(10000);
await browser.close();
import puppeteer from 'puppeteer';
const browser = await puppeteer.launch({ headless: false });
const page = await browser.newPage();
// Define our blocked extensions
const blockedExtensions = ['.png', '.css', '.jpg', '.jpeg', '.pdf', '.svg'];
// Use CDP session to block resources
await page.client().send('Network.setBlockedURLs', { urls: blockedExtensions });
await page.goto('https://soundcloud.com/tiesto/following');
await page.waitForTimeout(10000);
await browser.close();
Modifying the request
There's much more to intercepting requests than just aborting them though. We can change the payload, headers, query parameters, and even the base URL.
Let's go ahead and intercept and modify the initial request we fire off with the page.goto() by making it go to Mesto's following page instead.
- Playwright
- Puppeteer
import { chromium } from 'playwright';
const browser = await chromium.launch({ headless: false });
const page = await browser.newPage();
// Only listen for requests matching this regular expression
page.route(/soundcloud.com\/tiesto/, async (route) => {
// Continue the route, but replace "tiesto" in the URL with "mestomusic"
return route.continue({ url: route.request().url().replace('tiesto', 'mestomusic') });
});
await page.goto('https://soundcloud.com/tiesto/following');
await page.waitForTimeout(10000);
await browser.close();
import puppeteer from 'puppeteer';
const browser = await puppeteer.launch({ headless: false });
const page = await browser.newPage();
await page.setRequestInterception(true);
// Listen for all requests
page.on('request', async (req) => {
// If it doesn't match, continue the route normally
if (!/soundcloud.com\/tiesto/.test(req.url())) return req.continue();
// Otherwise, continue the route, but replace "tiesto"
// in the URL with "mestomusic"
await req.continue({ url: req.url().replace('tiesto', 'mestomusic') });
});
await page.goto('https://soundcloud.com/tiesto/following');
await page.waitForTimeout(10000);
await browser.close();
Note that this is not a redirect, because Tiësto's page was never even visited. The request was changed before it was even fulfilled.
Here's what we see when we run node index.js:
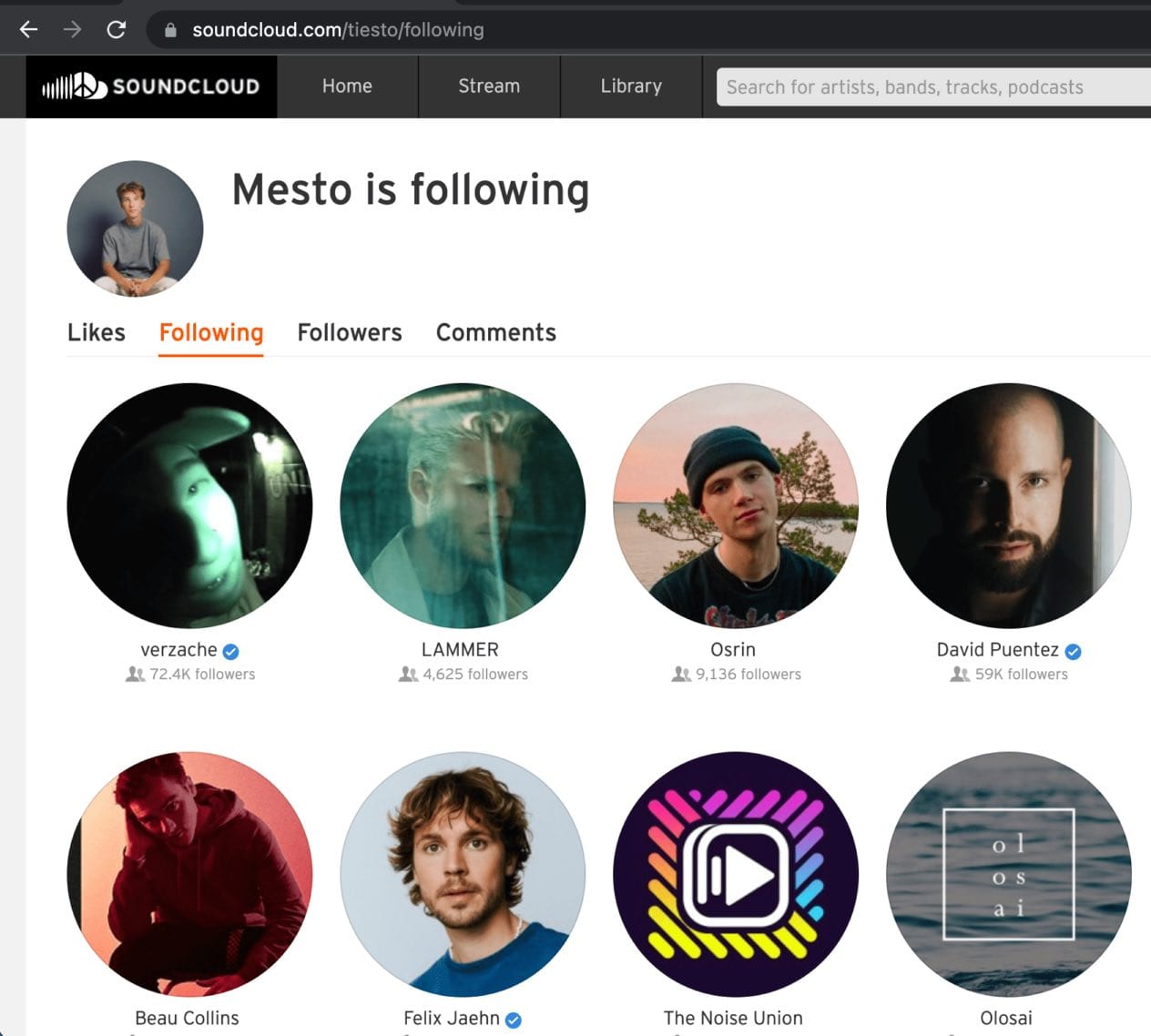
Next up
The next lesson will teach you how to use proxies in Playwright and Puppeteer in order to avoid blocking or to appear as if you are requesting from a different location.