How to scrape sites with a shadow DOM
The shadow DOM enables isolation of web components, but causes problems for those building web scrapers. Here's a workaround.
Each website is represented by an HTML DOM, a tree-like structure consisting of HTML elements (e.g. paragraphs, images, videos) and text. Shadow DOM allows the separate DOM trees to be attached to the main DOM while remaining isolated in terms of CSS inheritance and JavaScript DOM manipulation. The CSS and JavaScript codes of separate shadow DOM components do not clash, but the downside is that you can't access the content from outside.
Let's take a look at this page alodokter.com. If you click on the menu and open a Chrome debugger, you will see that the menu tree is attached to the main DOM as shadow DOM under the element <top-navbar-view id="top-navbar-view">.
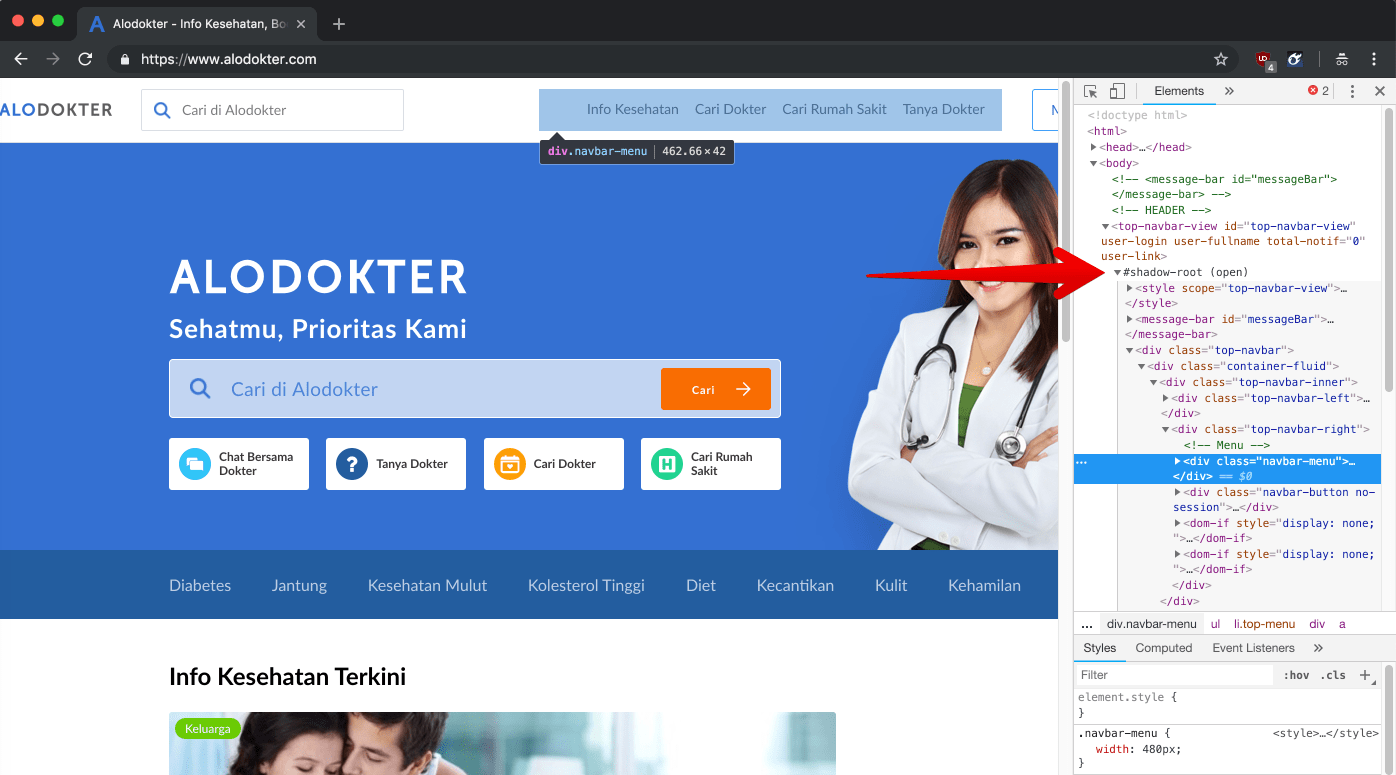
The rest of the content is rendered the same way. This makes it hard to scrape because document.body.innerText, document.getElementsByTagName('a'), and all others return an empty result.
The content of the menu can be accessed only via the shadowRoot property. If you use jQuery you can do the following:
// Find element that is shadow root of menu DOM tree.
const { shadowRoot } = document.getElementById('top-navbar-view');
// Create a copy of its HTML and use jQuery find links.
const links = $(shadowRoot.innerHTML).find('a');
// Get URLs from link elements.
const urls = links.map((obj, el) => el.href);
However, this isn't very convenient, because you have to find the root element of each component you want to work with, and you can't take advantage of all the scripts and tools you already have.
Instead of that, we can replace the content of each element containing shadow DOM with the HTML of shadow DOM.
// Iterate over all elements in the main DOM.
for (const el of document.getElementsByTagName('*')) {
// If element contains shadow root then replace its
// content with the HTML of shadow DOM.
if (el.shadowRoot) el.innerHTML = el.shadowRoot.innerHTML;
}
After you run this, you can access all the elements and content using jQuery or plain JavaScript. The downside is that it breaks all the interactive components because you create a new copy of the shadow DOM HTML content without the JavaScript code and CSS attached, so this must be done after all the content has been rendered.
Some websites may contain shadow DOMs recursively inside of shadow DOMs. In these cases, we must replace them with HTML recursively:
// Returns HTML of given shadow DOM.
const getShadowDomHtml = (shadowRoot) => {
let shadowHTML = '';
for (const el of shadowRoot.childNodes) {
shadowHTML += el.nodeValue || el.outerHTML;
}
return shadowHTML;
};
// Recursively replaces shadow DOMs with their HTML.
const replaceShadowDomsWithHtml = (rootElement) => {
for (const el of rootElement.querySelectorAll('*')) {
if (el.shadowRoot) {
replaceShadowDomsWithHtml(shadowRoot);
el.innerHTML += getShadowDomHtml(el.shadowRoot);
}
}
};
replaceShadowDomsWithHtml(document.body);