Block requests in Puppeteer
blockRequestsUnfortunately, in the recent version of Puppeteer, request interception disables the native cache and slows down the Actor significantly. Therefore, it's not recommended to follow the examples shown in this article. Instead, use blockRequests utility function from Crawlee. It works through different paths and doesn't slow down your process.
When using Puppeteer, often a webpage will load many resources that are not actually necessary for your use case. For example page could be loading many tracking libraries, that are completely unnecessary for most crawlers, but will cause the page to use more traffic and load slower.
For example for this web page: https://edition.cnn.com/ If we run an Actor that measures extracted downloaded data from each response until the page is fully loaded, we get these results:
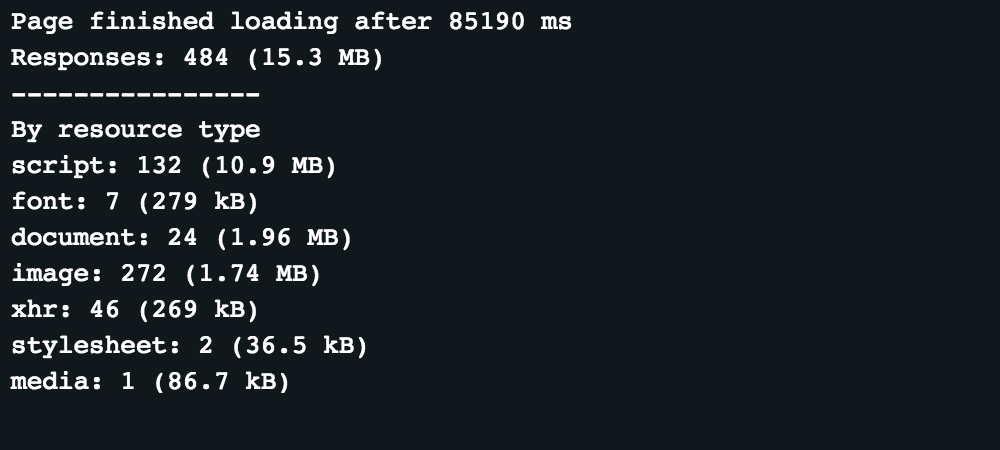
Now if we want to optimize this to keep the webpage looking the same, but ignore unnecessary requests, then after
const page = await browser.newPage();
we could can use this piece of code
await page.setRequestInterception(true);
page.on('request', (request) => {
if (someCondition) request.abort();
else request.continue();
});
Where someCondition is a custom condition (not actually implemented in the code above) that checks whether a request should be aborted.
For our example we will only disable some tracking scripts and then check if everything looks the same.
Here is the code used:
await page.setRequestInterception(true);
page.on('request', (request) => {
const url = request.url();
const filters = [
'livefyre',
'moatad',
'analytics',
'controltag',
'chartbeat',
];
const shouldAbort = filters.some((urlPart) => url.includes(urlPart));
if (shouldAbort) request.abort();
else request.continue();
});
With this code set up this is the output:
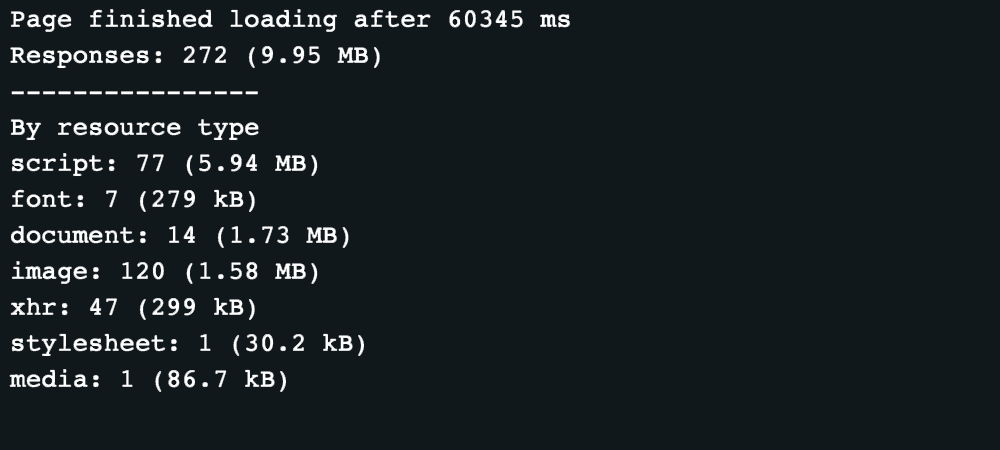
And except for different ads, the page should look the same.
From this we can see that just by blocking a few analytics and tracking scripts the page was loaded nearly 25 seconds faster and downloaded 35% less data (approximately since the data is measured after it's decompressed).
Hopefully this helps you make your solutions faster and use fewer resources.