Crawling with search
In this lesson, we will start with a simpler example of scraping HTML based websites with limited pagination.
Limiting pagination is a common practice on e-commerce sites. It makes sense: a real user will never want to look through more than 200 pages of results - only bots love unlimited pagination. Fortunately, there are ways to overcome this limit while keeping our code clean and generic.

In a rush? Skip the tutorial and get the full code example.
How to overcome the limit
Websites usually limit the pagination of a single (sub)category to somewhere between 1,000 to 20,000 listings. The site might have over a million listings in total. Without a proven algorithm, it will be very manual and almost impossible to scrape all listings.
We will first look at a couple of ideas that don't work so well and then present the final robust solution.
Going deeper into subcategories
This is usually the first solution that comes to mind. You traverse the smallest subcategories and hope that those are below the pagination limits. Unfortunately, there are two big problems with this approach:
- Any subcategory might be bigger than the pagination limit.
- Some listings from the parent category might not be present in any subcategory.
While you can often manually test if the second problem is true on the site, the first problem is a hard blocker. You might be just lucky, and it may work on this site but usually, traversing subcategories is not enough. It can be used as a first step of the solution but not as the solution itself.
Using filters
Most websites also provide a way for the user to select search filters. These allow a more granular level of search than categories and can be combined with them. Common filters allow you to select a color, size, location and similar attributes.
At first, it might seem like an easy solution. Enqueue all possible filter combinations and that should be so granular that it will never hit a pagination limit. Unfortunately, this solution is still far from good.
- No guarantee that some products won't slip through the chosen filter combinations.
- The resulting split might be too granular and end up having too many tiny paginations with many duplicate products. This leads to scraping a lot more pages than necessary and makes analytics much harder.
Using filter ranges
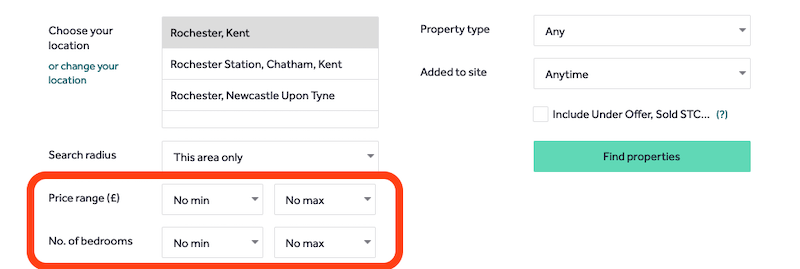
The best option is to use only a specific type of filter that can be used as a range. The most common one is price range but there may be others like the apartment size, etc. You can split the pagination pages to only contain listings within that range, e.g. products costing between $10 and $20.
This has several benefits:
- All listings can eventually be found in a range.
- The ranges do not overlap, so we scrape the smallest possible number of pages and avoid duplicate listings.
- Ranges can be controlled by a generic algorithm that can be reused for different sites.
Splitting pages with range filters
In the previous section, we analyzed different options to split the pages to overcome the pagination limit. We have chosen range filters as the most reliable way to do that. In this section, we will discuss a generic algorithm to work with ranges, look at a few special cases and then write an example crawler.
The algorithm
The core algorithm can be used on any (even overlapping) range. This is a simplified presentation, we will discuss the details later.
- We choose a few pivot ranges with a similar number of products and enqueue them. For example, $0-$10, $100-$1000, $1000-$10000, $10000-.
- For each range, we open the page and check if the listings are below the limit. If yes, we continue to step 3. If not, we split the filter in half, e.g. $0-$10 to $0-$5 and $5-$10 and enqueue those again. We recursively repeat step 2 for each range as long as needed.
- We now have a pagination URL that is below the limit, we enqueue it under a pagination label and start enqueuing products.
Because the algorithm is recursive, we don't need to think about how big the final ranges should be, the algorithm will find them over time.
Special cases to look for
We have the base algorithm, but before we start coding, let's answer a few questions to get more insight.
Can the ranges overlap?
Some sites will allow you to construct non-overlapping ranges. For example, you can set the ranges with cents, e.g. $0-$4.99, $5-$9.99, etc. If that is possible, create the pivot ranges this way, too.
Non-overlapping ranges should remove the possibility of duplicate products (unless a listing has multiple values) and the lowest number of pages.
If the website supports only overlapping ranges (e.g. $0-$5, $5–10), it is not a big problem. Only a small portion of the listings will be duplicates, and they can be removed using a request queue.
Can a listing have more values?
In rare cases, a listing can have more than one value that you are filtering in a range. A typical example is Amazon, where each product has several offers and those offers have different prices. If any of those offers is within the range, the product is shown.
No easy way exists to get around this but the price range split works even with duplicate listings, use a JS set or request queue to deduplicate them.
How is the range passed to the URL?
In the easiest case, you can pass the range directly in the page's URL. For example, https://example.com/products?price=0-10. Sometimes, you will need to do some query composition because the price range might be encoded together with more information into a single parameter.
Some sites don't have page URLs with filters and instead load the filtered products via XHRs. Those can be GET or POST requests with varying URL and payload syntax.
The nice thing here is that if you get to understand how their internal API works, you can have it return more products per page or extract full product details just from this single request.
In addition, XHRs are smaller and faster than loading an HTML page. On the other hand, you should not overly abuse them (with setting overly large limits), as this can expose you.
Does the website show the number of products for each filtered page?
If it does, it's a nice bonus. It gives us a way to check if we are over or below the pagination limit and helps with analytics.
If it doesn't, we have to find a different way to check if the number of listings is within a limit. One option is to go to the last allowed page of the pagination. If that page is still full of products, we can assume the filter is over the limit.
How to handle (open) ends of the range
Logically, every full (price) range starts at 0 and ends at infinity. But the way this is encoded will differ on each site. The end of the price range can be either closed (0) or open (infinity). Open ranges require special handling when you split them (we will get to that).
Most sites will let you start with 0 (there might be exceptions, where you will have to make the start open), so we can use just that. The high end is more complicated. Because you don't know the biggest price, it is best to leave it open and handle it specially. Internally you can assign null to the value.
Here are a few examples of a query parameter with an open and closed high-end range:
- Open:
p:100-(higher than 100), Closed:p:100-200(between 100 and 200) - Open:
min_price=100, Closed:min_price=100&max_price=200
Can the range exceed the limit on a single value?
In very rare cases, a site will have so many listings that a single value (e.g. $100 or $4.99) will include a number of listings over the limit. The basic algorithm will recurse until the min value equals the max value and then stop because it cannot split that single value anymore.
In this rare case, you will need to add another range or other filters to combine it to get an even deeper split.
Implementing a range filter
This section shows a code example implementing our solution for an imaginary website. Writing a real solution will bring up more complex problems but the previous section should prepare you for some of them.
First, let's define our imaginary site:
- It has a single
/productspath that contains all the products that we want to scrape. - Max pagination limit is 1000.
- The site contains over a million products.
- It allows for filtering over a price range with query parameters
min_priceandmax_price. - If
min_priceormax_priceare not defined, it opens that end of the range (all products up to or all products over that). - The site allows to specify the price in cents.
- Pagination is done via
pagequery parameter.
Define and enqueue pivot ranges
This step is not necessary but it is useful. The algorithm doesn't start with splitting over too large or too small values.
import { Actor } from 'apify';
import { CheerioCrawler } from 'crawlee';
await Actor.init();
const MAX_PRODUCTS_PAGINATION = 1000;
// Just an example, choose what makes sense for your site
const PIVOT_PRICE_RANGES = [
{ min: 0, max: 9.99 },
{ min: 10, max: 99.99 },
{ min: 100, max: 999.99 },
{ min: 1000, max: 9999.99 },
{ min: 10000, max: null }, // open-ended
];
// Let's create a helper function for creating the filter URLs, you can move those to a utils.js file
const createFilterUrl = ({ min, max }) => {
const minString = `min_price=${min}`;
// We don't want to pass the parameter at all if it is null (open-ended)
const maxString = max ? `&max_price=${max}` : '';
return `https://www.mysite.com/products?${minString}${maxString}`;
};
// And another helper for getting filters back from the URL, we could also pass them in userData
const getFiltersFromUrl = (url) => {
const min = Number(url.match(/min_price=([0-9.]+)/)[1]);
// Max price might be empty
const maxMatch = url.match(/max_price=([0-9.]+)/);
const max = maxMatch ? Number(maxMatch[1]) : null;
return { min, max };
};
// Actor setup things here
const crawler = new CheerioCrawler({
async requestHandler(context) {
// ...
},
});
// Let's create the pivot requests
const initialRequests = [];
for (const { min, max } of PIVOT_PRICE_RANGES) {
initialRequests.push({
url: createFilterUrl({ min, max }),
label: 'FILTER',
});
}
// Let's start the crawl
await crawler.run(initialRequests);
await Actor.exit();
Define the logic for the FILTER page
import { CheerioCrawler } from 'crawlee';
// Doesn't matter what Crawler class we choose
const crawler = new CheerioCrawler({
// Crawler options here
// ...
async requestHandler({ request, $ }) {
const { label } = request;
if (label === 'FILTER') {
// Of course, change the selectors and make it more robust
const numberOfProducts = Number($('.product-count').text());
// The filter is either good enough of we have to split it
if (numberOfProducts <= MAX_PRODUCTS_PAGINATION) {
// We pass the URL for scraping, we could optimize it so the page is not opened again
await crawler.addRequests([{
url: `${request.url}&page=1`,
userData: { label: 'PAGINATION' },
}]);
} else {
// Here we have to split the filter
// To be continued...
}
}
if (label === 'PAGINATION') {
// We know we are under the limit here
// Enqueue next page as long as possible
// Enqueue or scrape products normally
}
},
});
Split price filters
We have the base of the crawler set up. The last part we are missing is the price filter splitting. Let's use a generic function for this. We can place it into the utils.js file.
// utils.js
export function splitFilter(filter) {
const { min, max } = filter;
// Don't forget that max can be null and we have to handle that situation
if (max && min > max) {
throw new Error(`WRONG FILTER - min(${min}) is greater than max(${max})`);
}
// We crate a middle value for the split. If max in null, we will use double min as the middle value
const middle = max
? min + Math.floor((max - min) / 2)
: min * 2;
// We have to do the Math.max and Math.min to prevent having min > max
const filterMin = {
min,
max: Math.max(middle, min),
};
const filterMax = {
min: max ? Math.min(middle + 1, max) : middle + 1,
max,
};
// We return 2 new filters
return [filterMin, filterMax];
}
Enqueue the filters
Let's finish the crawler now. This code example will go inside the else block of the previous crawler example.
const { min, max } = getFiltersFromUrl(request.url);
// Our generic splitFilter function doesn't account for decimal values so we will have to convert to cents and back to dollars
const newFilters = splitFilter({ min: min * 100, max: max * 100 });
// And we enqueue those 2 new filters so the process will recursively repeat until all pages get to the PAGINATION phase
const requestsToEnqueue = [];
for (const filter of newFilters) {
requestsToEnqueue.push({
// Remember that we have to convert back from cents to dollars
url: createFilterUrl({ min: filter.min / 100, max: filter.max / 100 }),
label: 'FILTER',
});
}
await crawler.addRequests(requestsToEnqueue);
Summary
And that's it. We have an elegant solution for a complicated problem. In a real project, you would want to make this a bit more robust and save analytics data. This will let you know what filters you went through and how many products each of them had.
Check out the full code example.